%EA%B0%9C%EC%9D%B8%EC%A0%95%EB%B3%B4
-
 세계 최초 개인정보 보호 기술이 적용된 인공지능(AI) 반도체 개발
우리 대학 전기및전자공학부 유민수 교수 연구팀이 세계 최초로 `차등 프라이버시 기술이 적용된 인공지능(AI) 어플리케이션(Differentially private machine learning)'의 성능을 비약적으로 높이는 인공지능 반도체를 개발했다고 19일 밝혔다.
빅데이터 및 인공지능 기술의 발전과 함께 구글, 애플, 마이크로소프트 등 클라우드 서비스를 제공하는 기업들은 전 세계 수십억 명의 사용자들에게 인공지능 기술을 기반으로 여러 가지 서비스(머신러닝 애즈 어 서비스, ML-as-a-Service, MLaaS)를 제공하고 있다. 이러한 서비스 중에는, 대표적으로 유튜브나 페이스북 등에서 시청자의 개별 취향에 맞춰 동영상 콘텐츠나 상품 등을 추천하는 `개인화 추천 시스템 기술(예- 딥러닝 추천 모델, Deep Learning Recommendation Model)' 이나, 구글 포토(Photo) 와 애플 아이클라우드(iCloud) 등에서 사진을 인물 별로 분류해주는 `안면 인식 기술 (예- 합성곱 신경망 네트워크 안면 인식, Convolutional Neural Network based Face Recognition)' 등이 있다.
이와 같은 서비스는 사용자의 정보를 대량으로 수집해, 이를 기반으로 인공지능 알고리즘의 정확도와 성능을 개선한다. 이 과정에서 필연적으로 많은 양의 사용자 정보가 서비스 제공 기업의 데이터 센터로 전송되고, 민감한 개인정보나 파일들이 저장되고 사용되는 과정에서 정보가 유출되는 문제가 발생하기도 한다.
또한 이러한 문제는 최근 주목받는 대형 인공지능 모델의 경우에 더 쉽게 발생하는 경향이 있으며, 실제 구글에서 사용하는 대화형 인공지능 모델인 GPT-2의 경우, 특정 단어들을 이야기했을 때 사용자의 개인정보 등을 유출하는 문제를 보였다. [참고1] 유사사례로서 국내에서 2020년 화제가 되었던 스캐터랩의 인공지능 챗봇 이루다의 경우에도 비슷한 문제가 불거진 적이 있다. [참고2]
[참고1] https://ai.googleblog.com/2020/12/privacy-considerations-in-large.html
[참고2] https://n.news.naver.com/mnews/article/092/0002243051?sid=105
이에 애플, 구글, 마이크로소프트 등 빅 테크 기업에서는 `차등 프라이버시 (differential privacy)' 기술을 크게 주목하고 있다. 차등 프라이버시 기술은 학습에 사용되는 그라디언트(gradient, 학습 방향 기울기)에 잡음(노이즈)를 섞음으로써 인공지능 모델로부터 사용자의 개인정보를 유출하는 모든 종류의 공격을 방어할 수 있다.
하지만 이러한 장점에도 불구하고, 차등 프라이버시 기술 적용 시, 기존 대비 어플리케이션의 속도와 성능이 크게 하락하는 문제 때문에 아직까지 범용적으로 널리 적용되지는 못했다. 이는 차등 프라이버시 머신러닝 학습 과정이 일반적인 머신러닝 학습과 다른 특성을 보이고, 이로 인해 기존의 하드웨어에서 효과적으로 실행되지 않아 메모리 사용량, 학습 속도 및 하드웨어 활용도 (hardware utilization) 측면에서 비효율적이기 때문이다.
이에 유민수 교수 연구팀은 차등 프라이버시 기술의 성능 병목 구간을 분석해 해당 기술이 적용된 어플리케이션의 성능을 크게 시킬 수 있는 `차등 프라이버시 머신러닝을 위한 인공지능(AI) 반도체 칩'을 개발했다. 유민수 교수팀이 개발한 인공지능 반도체는 외적 기반 연산기와 덧셈기 트리 기반의 후처리 연산기 등으로 구성돼 있으며, 현재 가장 널리 사용되는 인공지능 프로세서인 구글 TPUv3 대비 차등 프라이버시 인공지능 학습 과정을 3.6 배 빠르게 실행시킬 수 있고, 엔비디아의 최신 GPU A100 대비 10배 적은 자원으로 대등한 성능을 보인다고 연구팀 관계자는 설명했다. 또한 이번 개발을 통해서 기존 하드웨어의 한계로 널리 쓰이지 못했던 차등 정보보호 기술의 대중화에 도움을 줄 수 있을 것으로 기대된다고 전했다.
우리 대학 전기및전자공학부 박범식, 황랑기 연구원이 공동 제1 저자로, 윤동호, 최윤혁 연구원이 공동 저자로 참여한 이번 연구는 미국 시카고에서 열리는 컴퓨터 구조 분야 최우수 국제 학술대회인 `55th IEEE/ACM International Symposium on Microarchitecture(MICRO 2022)'에서 오늘 10월 발표될 예정이다. (논문명 : DiVa: An Accelerator for Differentially Private Machine Learning)
또한 이번 연구는 지금까지는 없던 차등 프라이버시가 적용된 인공지능 반도체를 세계 최초로 개발했다는 점에서 의의가 있으며, 차등 프라이버시 인공지능 기술을 대중화해 인공지능 기반 서비스 사용자들의 개인정보를 보호하는 데에 큰 도움을 줄 수 있을 것으로 보인다. 또한, 가속기의 성능 향상은 인공지능 연구 효율을 높여 차등 프라이버시 인공지능 모델의 정확도 개선에도 기여할 것으로 보인다.
한편 이번 연구는 한국연구재단, 삼성전자, 그리고 반도체설계교육센터 (IDEC, IC Design Education Center)의 지원을 받아 수행됐다.
2022.08.19 조회수 5628
세계 최초 개인정보 보호 기술이 적용된 인공지능(AI) 반도체 개발
우리 대학 전기및전자공학부 유민수 교수 연구팀이 세계 최초로 `차등 프라이버시 기술이 적용된 인공지능(AI) 어플리케이션(Differentially private machine learning)'의 성능을 비약적으로 높이는 인공지능 반도체를 개발했다고 19일 밝혔다.
빅데이터 및 인공지능 기술의 발전과 함께 구글, 애플, 마이크로소프트 등 클라우드 서비스를 제공하는 기업들은 전 세계 수십억 명의 사용자들에게 인공지능 기술을 기반으로 여러 가지 서비스(머신러닝 애즈 어 서비스, ML-as-a-Service, MLaaS)를 제공하고 있다. 이러한 서비스 중에는, 대표적으로 유튜브나 페이스북 등에서 시청자의 개별 취향에 맞춰 동영상 콘텐츠나 상품 등을 추천하는 `개인화 추천 시스템 기술(예- 딥러닝 추천 모델, Deep Learning Recommendation Model)' 이나, 구글 포토(Photo) 와 애플 아이클라우드(iCloud) 등에서 사진을 인물 별로 분류해주는 `안면 인식 기술 (예- 합성곱 신경망 네트워크 안면 인식, Convolutional Neural Network based Face Recognition)' 등이 있다.
이와 같은 서비스는 사용자의 정보를 대량으로 수집해, 이를 기반으로 인공지능 알고리즘의 정확도와 성능을 개선한다. 이 과정에서 필연적으로 많은 양의 사용자 정보가 서비스 제공 기업의 데이터 센터로 전송되고, 민감한 개인정보나 파일들이 저장되고 사용되는 과정에서 정보가 유출되는 문제가 발생하기도 한다.
또한 이러한 문제는 최근 주목받는 대형 인공지능 모델의 경우에 더 쉽게 발생하는 경향이 있으며, 실제 구글에서 사용하는 대화형 인공지능 모델인 GPT-2의 경우, 특정 단어들을 이야기했을 때 사용자의 개인정보 등을 유출하는 문제를 보였다. [참고1] 유사사례로서 국내에서 2020년 화제가 되었던 스캐터랩의 인공지능 챗봇 이루다의 경우에도 비슷한 문제가 불거진 적이 있다. [참고2]
[참고1] https://ai.googleblog.com/2020/12/privacy-considerations-in-large.html
[참고2] https://n.news.naver.com/mnews/article/092/0002243051?sid=105
이에 애플, 구글, 마이크로소프트 등 빅 테크 기업에서는 `차등 프라이버시 (differential privacy)' 기술을 크게 주목하고 있다. 차등 프라이버시 기술은 학습에 사용되는 그라디언트(gradient, 학습 방향 기울기)에 잡음(노이즈)를 섞음으로써 인공지능 모델로부터 사용자의 개인정보를 유출하는 모든 종류의 공격을 방어할 수 있다.
하지만 이러한 장점에도 불구하고, 차등 프라이버시 기술 적용 시, 기존 대비 어플리케이션의 속도와 성능이 크게 하락하는 문제 때문에 아직까지 범용적으로 널리 적용되지는 못했다. 이는 차등 프라이버시 머신러닝 학습 과정이 일반적인 머신러닝 학습과 다른 특성을 보이고, 이로 인해 기존의 하드웨어에서 효과적으로 실행되지 않아 메모리 사용량, 학습 속도 및 하드웨어 활용도 (hardware utilization) 측면에서 비효율적이기 때문이다.
이에 유민수 교수 연구팀은 차등 프라이버시 기술의 성능 병목 구간을 분석해 해당 기술이 적용된 어플리케이션의 성능을 크게 시킬 수 있는 `차등 프라이버시 머신러닝을 위한 인공지능(AI) 반도체 칩'을 개발했다. 유민수 교수팀이 개발한 인공지능 반도체는 외적 기반 연산기와 덧셈기 트리 기반의 후처리 연산기 등으로 구성돼 있으며, 현재 가장 널리 사용되는 인공지능 프로세서인 구글 TPUv3 대비 차등 프라이버시 인공지능 학습 과정을 3.6 배 빠르게 실행시킬 수 있고, 엔비디아의 최신 GPU A100 대비 10배 적은 자원으로 대등한 성능을 보인다고 연구팀 관계자는 설명했다. 또한 이번 개발을 통해서 기존 하드웨어의 한계로 널리 쓰이지 못했던 차등 정보보호 기술의 대중화에 도움을 줄 수 있을 것으로 기대된다고 전했다.
우리 대학 전기및전자공학부 박범식, 황랑기 연구원이 공동 제1 저자로, 윤동호, 최윤혁 연구원이 공동 저자로 참여한 이번 연구는 미국 시카고에서 열리는 컴퓨터 구조 분야 최우수 국제 학술대회인 `55th IEEE/ACM International Symposium on Microarchitecture(MICRO 2022)'에서 오늘 10월 발표될 예정이다. (논문명 : DiVa: An Accelerator for Differentially Private Machine Learning)
또한 이번 연구는 지금까지는 없던 차등 프라이버시가 적용된 인공지능 반도체를 세계 최초로 개발했다는 점에서 의의가 있으며, 차등 프라이버시 인공지능 기술을 대중화해 인공지능 기반 서비스 사용자들의 개인정보를 보호하는 데에 큰 도움을 줄 수 있을 것으로 보인다. 또한, 가속기의 성능 향상은 인공지능 연구 효율을 높여 차등 프라이버시 인공지능 모델의 정확도 개선에도 기여할 것으로 보인다.
한편 이번 연구는 한국연구재단, 삼성전자, 그리고 반도체설계교육센터 (IDEC, IC Design Education Center)의 지원을 받아 수행됐다.
2022.08.19 조회수 5628 -
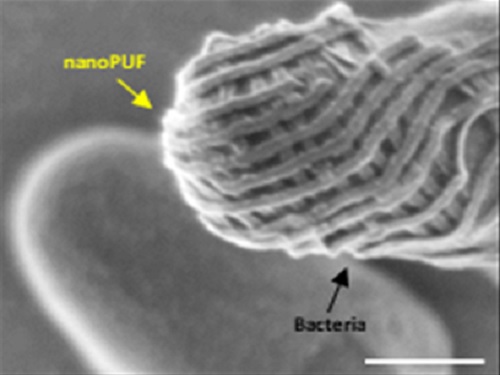 나노 크기 인공 지문으로 복제불가 사물인터넷 보안, 인증 원천기술 개발
우리 대학 신소재공학과 김상욱 교수 연구팀이 DGIST 로봇및기계전자공학과 김봉훈 교수, 성균관대 화학공학/고분자공학부 권석준 교수와 공동연구를 통해 사람의 지문과 같이 매번 다른 형태를 형성하는 무작위적인 분자조립 나노 패턴을 이용한 새로운 IoT(사물인터넷) 보안/인증 원천기술을 개발했다고 9일 밝혔다.
최근 IoT 기술이 발전함에 따라 다양한 기기들이 인터넷을 통해 연결된 초연결 시대가 도래하고 있다. 그러나 IoT 기기들의 해킹 사례가 빈번하게 보고되고 있으며, IoT 기술을 안전하게 사용할 수 있느냐에 대한 의문이 제기되는 실정이다.
우리 주위에 흔히 사용되는 인증 방법으로 사람의 지문이나 핸드폰 등에서 제공해주는 QR 패턴을 들 수 있다. 사람의 지문은 모든 사람에게 다르게 형성되므로 각 개인을 식별하기 위한 인증 매체로 오래전부터 사용돼왔으나, 그 크기가 눈에 보일 정도로 커서 쉽게 복제할 수 있다는 단점을 가지고 있다.
반면 최근까지도 코로나 방역에 큰 역할을 했던 QR코드는 사용할 때마다 매번 다른 패턴을 형성하므로 복제가 어렵지만, 새로이 패턴이 생길 때마다 무선통신으로 등록을 해야 하므로 에너지 소모가 크고 개인의 프라이버시가 침해되는 문제점이 지적되기도 했다.
이번에 공동연구팀이 개발한 인증기술은 김상욱 교수가 세계 최초/최고기술을 인정받고 있는 분자조립 나노 패턴 기술을 이용해 서로 다른 모양을 가지는 수십억 개의 나노 패턴을 저비용으로 만들어낼 수 있으며, 높은 보안 수준을 유지하면서도 초고속 인증이 가능하다. 또한 연구팀은 나노 크기의 소형화를 통해 눈에 보이지 않는 투명소자나 초소형 장치 또는 개미 혹은 박테리아에도 부착함으로써 미생물 인식 칩으로써의 활용 가능성도 제시했다.
공동연구팀이 개발한 기술은 복제 방지를 위한 다양한 하드웨어 인증시스템에 유용할 뿐만 아니라, 기존 소프트웨어 인증과 달리 전자기 펄스(EMP) 공격과 같은 최첨단 무기 체계에도 내구성이 있어 향후 군사 및 국가 안보 등에도 활용성이 높을 것으로 전망된다. 나아가 이상적인 난수 생성 소재 (true random number generator)로서의 활용성도 기대된다.
신소재공학과 김상욱 교수, DGIST 로봇및기계전자공학과 김봉훈 교수, 성균관대 화학공학/고분자공학부 권석준 교수가 공동 교신저자 및 KAIST 신소재공학과 졸업생인 김장환 박사가 제1 저자로 참여한 이번 연구는 전자공학 분야 최고 권위 학술지인 `네이처 일렉트로닉스(Nature electronics, JCR 상위 0.18 %)'에 7월 26일 字 게재됐다. (논문명 : Nanoscale physical unclonable function labels based on block co-polymer self-assembly).
또한 공동연구팀은 기술 개발 과정에서 국내 특허, 미국 특허, 유럽 특허 및 PCT를 출원해 이번 기술의 지적 재산권을 확보했다고 밝혔다. 해당 특허는 KAIST 교원 창업 회사인 `(주)소재창조'를 통해 사업화를 진행할 계획이다.
한편 이번 연구는 한국창의연구재단의 지원을 받아 수행됐다.
2022.08.09 조회수 5315
나노 크기 인공 지문으로 복제불가 사물인터넷 보안, 인증 원천기술 개발
우리 대학 신소재공학과 김상욱 교수 연구팀이 DGIST 로봇및기계전자공학과 김봉훈 교수, 성균관대 화학공학/고분자공학부 권석준 교수와 공동연구를 통해 사람의 지문과 같이 매번 다른 형태를 형성하는 무작위적인 분자조립 나노 패턴을 이용한 새로운 IoT(사물인터넷) 보안/인증 원천기술을 개발했다고 9일 밝혔다.
최근 IoT 기술이 발전함에 따라 다양한 기기들이 인터넷을 통해 연결된 초연결 시대가 도래하고 있다. 그러나 IoT 기기들의 해킹 사례가 빈번하게 보고되고 있으며, IoT 기술을 안전하게 사용할 수 있느냐에 대한 의문이 제기되는 실정이다.
우리 주위에 흔히 사용되는 인증 방법으로 사람의 지문이나 핸드폰 등에서 제공해주는 QR 패턴을 들 수 있다. 사람의 지문은 모든 사람에게 다르게 형성되므로 각 개인을 식별하기 위한 인증 매체로 오래전부터 사용돼왔으나, 그 크기가 눈에 보일 정도로 커서 쉽게 복제할 수 있다는 단점을 가지고 있다.
반면 최근까지도 코로나 방역에 큰 역할을 했던 QR코드는 사용할 때마다 매번 다른 패턴을 형성하므로 복제가 어렵지만, 새로이 패턴이 생길 때마다 무선통신으로 등록을 해야 하므로 에너지 소모가 크고 개인의 프라이버시가 침해되는 문제점이 지적되기도 했다.
이번에 공동연구팀이 개발한 인증기술은 김상욱 교수가 세계 최초/최고기술을 인정받고 있는 분자조립 나노 패턴 기술을 이용해 서로 다른 모양을 가지는 수십억 개의 나노 패턴을 저비용으로 만들어낼 수 있으며, 높은 보안 수준을 유지하면서도 초고속 인증이 가능하다. 또한 연구팀은 나노 크기의 소형화를 통해 눈에 보이지 않는 투명소자나 초소형 장치 또는 개미 혹은 박테리아에도 부착함으로써 미생물 인식 칩으로써의 활용 가능성도 제시했다.
공동연구팀이 개발한 기술은 복제 방지를 위한 다양한 하드웨어 인증시스템에 유용할 뿐만 아니라, 기존 소프트웨어 인증과 달리 전자기 펄스(EMP) 공격과 같은 최첨단 무기 체계에도 내구성이 있어 향후 군사 및 국가 안보 등에도 활용성이 높을 것으로 전망된다. 나아가 이상적인 난수 생성 소재 (true random number generator)로서의 활용성도 기대된다.
신소재공학과 김상욱 교수, DGIST 로봇및기계전자공학과 김봉훈 교수, 성균관대 화학공학/고분자공학부 권석준 교수가 공동 교신저자 및 KAIST 신소재공학과 졸업생인 김장환 박사가 제1 저자로 참여한 이번 연구는 전자공학 분야 최고 권위 학술지인 `네이처 일렉트로닉스(Nature electronics, JCR 상위 0.18 %)'에 7월 26일 字 게재됐다. (논문명 : Nanoscale physical unclonable function labels based on block co-polymer self-assembly).
또한 공동연구팀은 기술 개발 과정에서 국내 특허, 미국 특허, 유럽 특허 및 PCT를 출원해 이번 기술의 지적 재산권을 확보했다고 밝혔다. 해당 특허는 KAIST 교원 창업 회사인 `(주)소재창조'를 통해 사업화를 진행할 계획이다.
한편 이번 연구는 한국창의연구재단의 지원을 받아 수행됐다.
2022.08.09 조회수 5315