-
 혹시 나도 수면 질환? AI로 간단히 검사해 보세요
각종 장비를 몸에 부착한 채 병원에서 하룻밤을 보내야 하는 번거로운 검사 없이 웹사이트를 통해 간단히 수면 질환 위험도를 파악할 방법이 나왔다. 우리 대학 수리과학과 김재경 교수 연구팀이 삼성서울병원 주은연‧최수정 교수팀, 이화여대 서울병원 김지현 교수팀과 공동 연구를 통해 개발한 세 가지 수면 질환을 예측할 수 있는 알고리즘 ‘슬립스(SLEEPS‧SimpLe quEstionnairE Predicting Sleep disorders)’를 12일 공개했다.
‘잠이 보약’이라는 말처럼 수면은 정신적‧신체적 건강에 주요한 영향을 미친다. 성인의 60%가량이 수면 질환을 앓고 있지만, 관련하여 전문 의료진에게 문의한 비율은 6% 수준에 불과하다. 병원 방문을 꺼리는 원인 중 하나로는 수면 질환 진단을 받기 위해 시행하는 수면다원검사가 번거롭다는 이유가 있다.
공동연구진은 약 5,000명의 수면다원검사 결과를 기계 학습을 통해 학습시켜 수면 질환 위험도를 예측하는 알고리즘 ‘슬립스’를 개발했다. 슬립스에서 나이, 성별, 키, 체중, 최근 2주간의 수면 시 어려움, 수면 유지 어려움, 기상 시 어려움, 수면 패턴에 대한 만족도, 수면이 일상 기능에 미치는 영향 등 간단한 9개의 질문에 답하는 것만으로 만성불면증, 수면호흡장애, 수면호흡장애를 동반한 불면증의 위험도를 90%의 정확도로 예측할 수 있다. 가령, 슬립스 검사 결과 수면호흡장애 위험도가 50%라는 결과가 나왔다면, 실제 수면다원검사를 시행했을 때 수면호흡장애가 발견될 확률이 50%임을 의미한다.
제1 저자인 하석민 미국 MIT 박사과정생(前 IBS 의생명 수학 그룹 연구원)은 “미국 하버드대 연구팀도 AI 기반 수면 질환 검사 알고리즘을 개발한 바 있으나, 이 시스템은 목둘레, 혈압 등 쉽게 답하기 어려운 문항이 포함되어 있어 사용이 까다로웠다”며 “또한, 하버드대 연구팀의 시스템은 예측 정확도도 70% 정도에 그쳤다”고 말했다.
슬립스 사이트(www.sleep-math.com)를 통해 누구나 수면 질환 여부를 예측해볼 수 있다. 현재 본인의 상태를 기준으로 몸무게 변화나 나이가 듦에 따른 수면 질환 위험도 변화도 살펴볼 수 있다.
김재경 교수는 “이번 연구는 수학으로 우리가 직면한 건강 문제를 해결해보고자 하는 시도에서 시작됐고, 중요하지만 쉽게 간과할 수 있는 수면 질환에 기계 학습을 접목했다”며 “수면 질환 진단의 복잡한 과정을 줄인 만큼, 많은 사람이 슬립스를 통해 자신의 수면 건강을 알 수 있는 계기가 되길 바란다”고 말했다.
주은연 삼성서울병원 교수는 “슬립스는 간편한 수면 질환 자가 검진 시스템”이라며 “향후 건강검진 항목에 AI 기반 자가 검진 시스템을 포함한다면 잠재적인 수면 질환 환자들을 스크리닝하여 수면 질환으로 인해 발생하는 수많은 질병을 선제적으로 예방할 수 있을 것”이라고 말했다.
슬립스 개발 성과는 지난 9월 의료 건강 분야 국제학술지 ‘Journal of Medical Internet Research’에 실린 바 있다.
혹시 나도 수면 질환? AI로 간단히 검사해 보세요
각종 장비를 몸에 부착한 채 병원에서 하룻밤을 보내야 하는 번거로운 검사 없이 웹사이트를 통해 간단히 수면 질환 위험도를 파악할 방법이 나왔다. 우리 대학 수리과학과 김재경 교수 연구팀이 삼성서울병원 주은연‧최수정 교수팀, 이화여대 서울병원 김지현 교수팀과 공동 연구를 통해 개발한 세 가지 수면 질환을 예측할 수 있는 알고리즘 ‘슬립스(SLEEPS‧SimpLe quEstionnairE Predicting Sleep disorders)’를 12일 공개했다.
‘잠이 보약’이라는 말처럼 수면은 정신적‧신체적 건강에 주요한 영향을 미친다. 성인의 60%가량이 수면 질환을 앓고 있지만, 관련하여 전문 의료진에게 문의한 비율은 6% 수준에 불과하다. 병원 방문을 꺼리는 원인 중 하나로는 수면 질환 진단을 받기 위해 시행하는 수면다원검사가 번거롭다는 이유가 있다.
공동연구진은 약 5,000명의 수면다원검사 결과를 기계 학습을 통해 학습시켜 수면 질환 위험도를 예측하는 알고리즘 ‘슬립스’를 개발했다. 슬립스에서 나이, 성별, 키, 체중, 최근 2주간의 수면 시 어려움, 수면 유지 어려움, 기상 시 어려움, 수면 패턴에 대한 만족도, 수면이 일상 기능에 미치는 영향 등 간단한 9개의 질문에 답하는 것만으로 만성불면증, 수면호흡장애, 수면호흡장애를 동반한 불면증의 위험도를 90%의 정확도로 예측할 수 있다. 가령, 슬립스 검사 결과 수면호흡장애 위험도가 50%라는 결과가 나왔다면, 실제 수면다원검사를 시행했을 때 수면호흡장애가 발견될 확률이 50%임을 의미한다.
제1 저자인 하석민 미국 MIT 박사과정생(前 IBS 의생명 수학 그룹 연구원)은 “미국 하버드대 연구팀도 AI 기반 수면 질환 검사 알고리즘을 개발한 바 있으나, 이 시스템은 목둘레, 혈압 등 쉽게 답하기 어려운 문항이 포함되어 있어 사용이 까다로웠다”며 “또한, 하버드대 연구팀의 시스템은 예측 정확도도 70% 정도에 그쳤다”고 말했다.
슬립스 사이트(www.sleep-math.com)를 통해 누구나 수면 질환 여부를 예측해볼 수 있다. 현재 본인의 상태를 기준으로 몸무게 변화나 나이가 듦에 따른 수면 질환 위험도 변화도 살펴볼 수 있다.
김재경 교수는 “이번 연구는 수학으로 우리가 직면한 건강 문제를 해결해보고자 하는 시도에서 시작됐고, 중요하지만 쉽게 간과할 수 있는 수면 질환에 기계 학습을 접목했다”며 “수면 질환 진단의 복잡한 과정을 줄인 만큼, 많은 사람이 슬립스를 통해 자신의 수면 건강을 알 수 있는 계기가 되길 바란다”고 말했다.
주은연 삼성서울병원 교수는 “슬립스는 간편한 수면 질환 자가 검진 시스템”이라며 “향후 건강검진 항목에 AI 기반 자가 검진 시스템을 포함한다면 잠재적인 수면 질환 환자들을 스크리닝하여 수면 질환으로 인해 발생하는 수많은 질병을 선제적으로 예방할 수 있을 것”이라고 말했다.
슬립스 개발 성과는 지난 9월 의료 건강 분야 국제학술지 ‘Journal of Medical Internet Research’에 실린 바 있다.
2023.12.14
조회수 13114
-
 2.4배 가격 효율적인 챗GPT 핵심 AI반도체 개발
오픈AI가 출시한 챗GPT는 전 세계적으로 화두이며 이 기술이 가져올 변화에 모두 주목하고 있다. 이 기술은 거대 언어 모델을 기반으로 하고 있다. 거대 언어 모델은 기존 인공지능과는 달리 전례 없는 큰 규모의 인공지능 모델이다. 이를 운영하기 위해서는 수많은 고성능 GPU가 필요해, 천문학적인 컴퓨팅 비용이 든다는 문제점이 있다.
우리 대학 전기및전자공학부 김주영 교수 연구팀이 챗GPT에 핵심으로 사용되는 거대 언어 모델의 추론 연산을 효율적으로 가속하는 AI 반도체를 개발했다고 4일 밝혔다.
연구팀이 개발한 AI 반도체 ‘LPU(Latency Processing Unit)’는 거대 언어 모델의 추론 연산을 효율적으로 가속한다. 메모리 대역폭 사용을 극대화하고 추론에 필요한 모든 연산을 고속으로 수행 가능한 연산 엔진을 갖춘 AI 반도체이며, 자체 네트워킹을 내장하여 다수개 가속기로 확장이 용이하다. 이 LPU 기반의 가속 어플라이언스 서버는 업계 최고의 고성능 GPU인 엔비디아 A100 기반 슈퍼컴퓨터보다 성능은 최대 50%, 가격 대비 성능은 2.4배가량 높였다. 이는 최근 급격하게 생성형 AI 서비스 수요가 증가하고 있는 데이터센터의에서 고성능 GPU를 대체할 수 있을 것으로 기대한다.
이번 연구는 김주영 교수의 창업기업인 ㈜하이퍼엑셀에서 수행했으며 미국시간 7월 12일 샌프란시스코에서 진행된 국제 반도체 설계 자동화 학회(Design Automation Conference, 이하 DAC)에서 공학 부문 최고 발표상(Engineering Best Presentation Award)을 수상하는 쾌거를 이뤘다.
DAC은 국제 반도체 설계 분야의 대표 학회이며, 특히 전자 설계 자동화(Electronic Design Automation, EDA)와 반도체 설계자산(Semiconductor Intellectual Property, IP) 기술 관련하여 세계적인 반도체 설계 기술을 선보이는 학회다. DAC에는 인텔, 엔비디아, AMD, 구글, 마이크로소프트, 삼성, TSMC 등 세계적인 반도체 설계 기업이 참가하며, 하버드대학교, MIT, 스탠퍼드대학교 등 세계 최고의 대학도 많이 참가한다.
세계적인 반도체 기술들 사이에서 김 교수팀이 거대 언어 모델을 위한 AI 반도체 기술로 유일하게 수상한 것은 매우 의미가 크다. 이번 수상으로 거대 언어 모델의 추론에 필요한 막대한 비용을 획기적으로 절감할 수 있는 AI 반도체 솔루션으로 세계 무대에서 인정받은 것이다.
우리 대학 김주영 교수는 “미래 거대 인공지능 연산을 위한 새로운 프로세서 ‘LPU’로 글로벌 시장을 개척하고, 빅테크 기업들의 기술력보다 우위를 선점하겠다”라며 큰 포부를 밝혔다.
2.4배 가격 효율적인 챗GPT 핵심 AI반도체 개발
오픈AI가 출시한 챗GPT는 전 세계적으로 화두이며 이 기술이 가져올 변화에 모두 주목하고 있다. 이 기술은 거대 언어 모델을 기반으로 하고 있다. 거대 언어 모델은 기존 인공지능과는 달리 전례 없는 큰 규모의 인공지능 모델이다. 이를 운영하기 위해서는 수많은 고성능 GPU가 필요해, 천문학적인 컴퓨팅 비용이 든다는 문제점이 있다.
우리 대학 전기및전자공학부 김주영 교수 연구팀이 챗GPT에 핵심으로 사용되는 거대 언어 모델의 추론 연산을 효율적으로 가속하는 AI 반도체를 개발했다고 4일 밝혔다.
연구팀이 개발한 AI 반도체 ‘LPU(Latency Processing Unit)’는 거대 언어 모델의 추론 연산을 효율적으로 가속한다. 메모리 대역폭 사용을 극대화하고 추론에 필요한 모든 연산을 고속으로 수행 가능한 연산 엔진을 갖춘 AI 반도체이며, 자체 네트워킹을 내장하여 다수개 가속기로 확장이 용이하다. 이 LPU 기반의 가속 어플라이언스 서버는 업계 최고의 고성능 GPU인 엔비디아 A100 기반 슈퍼컴퓨터보다 성능은 최대 50%, 가격 대비 성능은 2.4배가량 높였다. 이는 최근 급격하게 생성형 AI 서비스 수요가 증가하고 있는 데이터센터의에서 고성능 GPU를 대체할 수 있을 것으로 기대한다.
이번 연구는 김주영 교수의 창업기업인 ㈜하이퍼엑셀에서 수행했으며 미국시간 7월 12일 샌프란시스코에서 진행된 국제 반도체 설계 자동화 학회(Design Automation Conference, 이하 DAC)에서 공학 부문 최고 발표상(Engineering Best Presentation Award)을 수상하는 쾌거를 이뤘다.
DAC은 국제 반도체 설계 분야의 대표 학회이며, 특히 전자 설계 자동화(Electronic Design Automation, EDA)와 반도체 설계자산(Semiconductor Intellectual Property, IP) 기술 관련하여 세계적인 반도체 설계 기술을 선보이는 학회다. DAC에는 인텔, 엔비디아, AMD, 구글, 마이크로소프트, 삼성, TSMC 등 세계적인 반도체 설계 기업이 참가하며, 하버드대학교, MIT, 스탠퍼드대학교 등 세계 최고의 대학도 많이 참가한다.
세계적인 반도체 기술들 사이에서 김 교수팀이 거대 언어 모델을 위한 AI 반도체 기술로 유일하게 수상한 것은 매우 의미가 크다. 이번 수상으로 거대 언어 모델의 추론에 필요한 막대한 비용을 획기적으로 절감할 수 있는 AI 반도체 솔루션으로 세계 무대에서 인정받은 것이다.
우리 대학 김주영 교수는 “미래 거대 인공지능 연산을 위한 새로운 프로세서 ‘LPU’로 글로벌 시장을 개척하고, 빅테크 기업들의 기술력보다 우위를 선점하겠다”라며 큰 포부를 밝혔다.
2023.08.04
조회수 9104
-
 포스트 AI 시대 문학 저작권 보호와 미래형 창작 패러다임 도출에 도전한다
소셜 미디어와 같은 새로운 방송 환경과 생성 AI의 등장으로 현재의 문화 예술 창작 패러다임은 큰 도전을 맞이하고 있다. 특히 인간의 저작물 이용에 따른 정당한 대가 지급은 지속적인 창작 동기를 유지하며 산업 발전을 이끌어낼 수 있는 저작권 체계의 핵심 전제인데, 저작물 이용이 활발한 방송분야에서 창작자들이 공정한 보상을 받을 수 있는 저작물 이용 모니터링과 정확한 정산·분배 시스템의 부재가 큰 문제로 제기되고 있다.
이런 상황을 개선하기 위하여 우리 대학 문화기술대학원의 박주용 교수(복합계 물리학) 연구팀은 “문학예술 저작물의 정산·분배를 위한 방송 모니터링 기술 개발(한국지식재산연구원 주관, 원아이디랩·무하유· 한국문학저작원협회 참여)” 프로젝트를 2023년 7월 1일부로 시작했다고 3일 발표하였다. 이 프로젝트에서는 방송에서 사용되는 문학예술 저작물(시, 소설, 수필 등)의 저작권료를 징수·분배하기 위한 시스템 수립을 위해 이용 콘텐츠는 즉각적으로 탐지하는 기술을 개발한다.
이 프로젝트에서는 국내 방송 및 라디오의 음성을 추출하고 이를 텍스트로 전환(Speech-To-Text, STT)하여 이용된 저작물을 정확하게 탐지한 뒤, 문학 저작물을 상세하게 구분·목록화함으로써 지적 재산권을 보호하고 관리하는 기초 기술을 연구하게 된다. 카이스트 박주용 연구팀은 문학 저작물에 사용되는 한국어와 영어 음성을 인식하는 기술을 개발하고, 다량의 저작물을 연계하여 검색할 수 있는 네트워크를 구축하게 된다. 이를 통해 ‘창작의 미래 기술’이라 불리며 큰 관심을 받고 있지만 지금까지는 인간 저작물을 무단·무분별하게 사용함으로써 비판받고 있는 ‘생성 AI’의 연구에 정당한 대가를 지불한 고품질의 적절한 저작물을 선별해 용도와 분야에 맞게 사용하는 것을 가능하게 할 것으로 기대되고 있다.
우리 대학 포스트 AI 연구소장이기도 한 박 교수는 “본 저작권 탐지 시스템과 이미 활발하게 진행 중인 문학 생성 AI 연구를 연계하여 인간 창의성 보호와 생성 AI의 고도화라는 두 마리 토끼를 잡음으로써 과학과 디지털 인문학이 긴밀하게 융합된 미래형 창작 패러다임을 설계하고 싶다”는 포부를 밝히기도 하였다.
이번 연구는 한국콘텐츠진흥원의 지원을 받아 30개월 동안 수행되며, 총 예산은 30억 원이다.
포스트 AI 시대 문학 저작권 보호와 미래형 창작 패러다임 도출에 도전한다
소셜 미디어와 같은 새로운 방송 환경과 생성 AI의 등장으로 현재의 문화 예술 창작 패러다임은 큰 도전을 맞이하고 있다. 특히 인간의 저작물 이용에 따른 정당한 대가 지급은 지속적인 창작 동기를 유지하며 산업 발전을 이끌어낼 수 있는 저작권 체계의 핵심 전제인데, 저작물 이용이 활발한 방송분야에서 창작자들이 공정한 보상을 받을 수 있는 저작물 이용 모니터링과 정확한 정산·분배 시스템의 부재가 큰 문제로 제기되고 있다.
이런 상황을 개선하기 위하여 우리 대학 문화기술대학원의 박주용 교수(복합계 물리학) 연구팀은 “문학예술 저작물의 정산·분배를 위한 방송 모니터링 기술 개발(한국지식재산연구원 주관, 원아이디랩·무하유· 한국문학저작원협회 참여)” 프로젝트를 2023년 7월 1일부로 시작했다고 3일 발표하였다. 이 프로젝트에서는 방송에서 사용되는 문학예술 저작물(시, 소설, 수필 등)의 저작권료를 징수·분배하기 위한 시스템 수립을 위해 이용 콘텐츠는 즉각적으로 탐지하는 기술을 개발한다.
이 프로젝트에서는 국내 방송 및 라디오의 음성을 추출하고 이를 텍스트로 전환(Speech-To-Text, STT)하여 이용된 저작물을 정확하게 탐지한 뒤, 문학 저작물을 상세하게 구분·목록화함으로써 지적 재산권을 보호하고 관리하는 기초 기술을 연구하게 된다. 카이스트 박주용 연구팀은 문학 저작물에 사용되는 한국어와 영어 음성을 인식하는 기술을 개발하고, 다량의 저작물을 연계하여 검색할 수 있는 네트워크를 구축하게 된다. 이를 통해 ‘창작의 미래 기술’이라 불리며 큰 관심을 받고 있지만 지금까지는 인간 저작물을 무단·무분별하게 사용함으로써 비판받고 있는 ‘생성 AI’의 연구에 정당한 대가를 지불한 고품질의 적절한 저작물을 선별해 용도와 분야에 맞게 사용하는 것을 가능하게 할 것으로 기대되고 있다.
우리 대학 포스트 AI 연구소장이기도 한 박 교수는 “본 저작권 탐지 시스템과 이미 활발하게 진행 중인 문학 생성 AI 연구를 연계하여 인간 창의성 보호와 생성 AI의 고도화라는 두 마리 토끼를 잡음으로써 과학과 디지털 인문학이 긴밀하게 융합된 미래형 창작 패러다임을 설계하고 싶다”는 포부를 밝히기도 하였다.
이번 연구는 한국콘텐츠진흥원의 지원을 받아 30개월 동안 수행되며, 총 예산은 30억 원이다.
2023.08.03
조회수 5551
-
 한국 법체계 발전 메커니즘 규명에 나선다
우리나라의 법률은 지난 30년간 법령 개수, 조문, 글자 수 등이 급격하게 늘어나면서 미국 연방 법전보다도 더욱 복잡해지며 법률 접근성이 떨어지고 있어 법령정보 제공의 지능화가 필요한 시점이다. 이에 현 법체계의 복잡성과 강건성(robustness)을 규명하고, 시대별 분석을 통해 우리 법이 어떻게 발전해왔는지 알아냄으로써 미래 입법 방향을 예측하는 연구가 필요하다.
우리 대학 문화기술대학원 박주용 교수(복합계 물리학), 문술미래전략대학원 박태정 교수(법 발전학) 공동연구팀은 국내 법령 데이터와 국제 조약 데이터를 전수 수집한 뒤 복합계 네트워크로 구성하여 분석하는 ‘포스트 AI 시대 법 발전학’ 연구를 수행해 우리 법체계의 안정성을 제고하고 대중의 법률에 대한 이해를 높일 수 있는 섬세한 시각화가 가능한 그래프 데이터베이스를 구축할 계획임을 16일 밝혔다.
법 발전학은 국가 발전을 위한 적절한 법과 제도를 설계하는 학문으로서, 법∙과학기술∙문화가 국가 발전에 미치는 영향을 종합적으로 예측하고 과학적 입법시스템을 고안하기 위한 노력이 국제적으로 활발히 이루어지고 있다. 특히 우리나라에서도 빅데이터, SNS, AI 등 생활 밀착형 정보 과학기술의 발달과법에 대한 대중들이 관심과 접근성이 증대하는 현실에서 과학과 법학이 함께 해야 한다는 목소리가 높아지고 있다.
이에 연구팀은 우리나라 법령데이터를 전수 수집하여 법률 사이의 연결관계를 나타내는 ‘복합계 네트워크’를 분석한 뒤 이를 기반으로 법률 전문가와 일반 국민이 원하는 법률정보를 손쉽고 빠르게 검색할 수 있는 그래프 형태의 데이터베이스를 2023년 6월 1일부터 3년에 걸쳐 구축할 계획이라고 밝혔다. 이러한 법학과 과학기술의 결합으로 법에 대한 일반 국민의 이해도를 높임으로써 일상생활에 도움이 되는 것은 물론, 조금 더 전문적인 과학기술기반 법률 서비스를 일컫는 ‘리걸테크(LegalTech)’ 분야에서 새로운 산업이 창출될 것으로 기대하고 있다.
우리 대학 포스트 AI 연구소장을 맡고 있는 이론물리학자 박주용 교수는 “법령끼리 서로를 인용하는 상호연결성에 주목해 법체계를 분석할 수 있는 과학적 방법론으로서 복합계 네트워크 과학, 기계학습∙자연어 처리 등의 AI 기술을 사용해 모든 일상생활에서 법의 적용을 받는 대중들이 사용하고 이해하기 쉬운 융합형 연구가 반드시 필요하다”고 밝혔다.
또한 법학자 박태정 교수는 “우리나라 법학계는 법의 적용과 해석에 관한 연구에 지나치게 편중되어 있고 입법학, 법정책학 및 법경제학 등 법이 나아가야 할 방향에 대한 연구는 상대적으로 미진한 편이다” 라고 지적하며 “법의 방향성을 연구하기 위해서는 법체계의 과학적 진단이 필수적이며 이러한 연구가 우리나라 입법 제도 발전에 큰 도움이 될 것으로 기대한다”고 밝혔다.
이번 연구는 한국연구재단의 지원을 받아 수행될 예정이며, 연구팀은 특히 학생과 젊은 연구원에 대한 적극적인 지원과, 국제심포지엄 개최 등을 통한 국제화에 힘을 쏟을 예정이다.
한국 법체계 발전 메커니즘 규명에 나선다
우리나라의 법률은 지난 30년간 법령 개수, 조문, 글자 수 등이 급격하게 늘어나면서 미국 연방 법전보다도 더욱 복잡해지며 법률 접근성이 떨어지고 있어 법령정보 제공의 지능화가 필요한 시점이다. 이에 현 법체계의 복잡성과 강건성(robustness)을 규명하고, 시대별 분석을 통해 우리 법이 어떻게 발전해왔는지 알아냄으로써 미래 입법 방향을 예측하는 연구가 필요하다.
우리 대학 문화기술대학원 박주용 교수(복합계 물리학), 문술미래전략대학원 박태정 교수(법 발전학) 공동연구팀은 국내 법령 데이터와 국제 조약 데이터를 전수 수집한 뒤 복합계 네트워크로 구성하여 분석하는 ‘포스트 AI 시대 법 발전학’ 연구를 수행해 우리 법체계의 안정성을 제고하고 대중의 법률에 대한 이해를 높일 수 있는 섬세한 시각화가 가능한 그래프 데이터베이스를 구축할 계획임을 16일 밝혔다.
법 발전학은 국가 발전을 위한 적절한 법과 제도를 설계하는 학문으로서, 법∙과학기술∙문화가 국가 발전에 미치는 영향을 종합적으로 예측하고 과학적 입법시스템을 고안하기 위한 노력이 국제적으로 활발히 이루어지고 있다. 특히 우리나라에서도 빅데이터, SNS, AI 등 생활 밀착형 정보 과학기술의 발달과법에 대한 대중들이 관심과 접근성이 증대하는 현실에서 과학과 법학이 함께 해야 한다는 목소리가 높아지고 있다.
이에 연구팀은 우리나라 법령데이터를 전수 수집하여 법률 사이의 연결관계를 나타내는 ‘복합계 네트워크’를 분석한 뒤 이를 기반으로 법률 전문가와 일반 국민이 원하는 법률정보를 손쉽고 빠르게 검색할 수 있는 그래프 형태의 데이터베이스를 2023년 6월 1일부터 3년에 걸쳐 구축할 계획이라고 밝혔다. 이러한 법학과 과학기술의 결합으로 법에 대한 일반 국민의 이해도를 높임으로써 일상생활에 도움이 되는 것은 물론, 조금 더 전문적인 과학기술기반 법률 서비스를 일컫는 ‘리걸테크(LegalTech)’ 분야에서 새로운 산업이 창출될 것으로 기대하고 있다.
우리 대학 포스트 AI 연구소장을 맡고 있는 이론물리학자 박주용 교수는 “법령끼리 서로를 인용하는 상호연결성에 주목해 법체계를 분석할 수 있는 과학적 방법론으로서 복합계 네트워크 과학, 기계학습∙자연어 처리 등의 AI 기술을 사용해 모든 일상생활에서 법의 적용을 받는 대중들이 사용하고 이해하기 쉬운 융합형 연구가 반드시 필요하다”고 밝혔다.
또한 법학자 박태정 교수는 “우리나라 법학계는 법의 적용과 해석에 관한 연구에 지나치게 편중되어 있고 입법학, 법정책학 및 법경제학 등 법이 나아가야 할 방향에 대한 연구는 상대적으로 미진한 편이다” 라고 지적하며 “법의 방향성을 연구하기 위해서는 법체계의 과학적 진단이 필수적이며 이러한 연구가 우리나라 입법 제도 발전에 큰 도움이 될 것으로 기대한다”고 밝혔다.
이번 연구는 한국연구재단의 지원을 받아 수행될 예정이며, 연구팀은 특히 학생과 젊은 연구원에 대한 적극적인 지원과, 국제심포지엄 개최 등을 통한 국제화에 힘을 쏟을 예정이다.
2023.06.16
조회수 7060
-
 111배 빠른 검색엔진용 CXL 3.0 기반 AI반도체 세계 최초 개발
최근 각광받고 있는 이미지 검색, 데이터베이스, 추천 시스템, 광고 등의 서비스들은 마이크로소프트, 메타, 알리바바 등의 글로벌 IT 기업들에서 활발히 제공되고 있다. 하지만 실제 서비스에서 사용되는 데이터 셋은 크기가 매우 커, 많은 양의 메모리를 요구하여 기존 시스템에서는 추가할 수 있는 메모리 용량에 제한이 있어 이러한 요구사항을 만족할 수 없었다.
우리 대학 전기및전자공학부 정명수 교수 연구팀(컴퓨터 아키텍처 및 메모리 시스템 연구실)에서 대용량으로 메모리 확장이 가능한 컴퓨트 익스프레스 링크 3.0 기술(Compute eXpress Link, 이하 CXL)을 활용해 검색 엔진을 위한 AI 반도체를 세계 최초로 개발했다고 25일 밝혔다.
최근 검색 서비스에서 사용되는 알고리즘은 근사 근접 이웃 탐색(Approximate Nearest Neighbor Search, ANNS)으로 어떤 데이터든지 특징 벡터로 표현할 수 있다. 특징 벡터란 데이터가 가지는 특징들 각각을 숫자로 표현해 나열한 것으로, 이들 사이의 거리를 통해 우리는 데이터 간의 유사도를 구할 수 있다. 하지만 벡터 데이터 용량이 매우 커서 이를 압축해 메모리에 적재하는 압축 방식과 메모리보다 큰 용량과 느린 속도를 가지는 저장 장치를 사용하는 스토리지 방식(마이크로소프트에서 사용 중)이 사용되어 왔다. 하지만 이들 각각은 낮은 정확도와 성능을 가지는 문제가 있었다.
이에 정명수 교수 연구팀은 메모리 확장의 제한이라는 근본적인 문제를 해결하기 위해 CXL이라는 기술에 주목했다. CXL은 CPU-장치 간 연결을 위한 프로토콜로, 가속기 및 메모리 확장기의 고속 연결을 제공한다. 또한 CXL 스위치를 통해 여러 대의 메모리 확장기를 하나의 포트에 연결할 수 있는 확장성을 제공한다. 하지만 CXL을 통한 메모리 확장은 로컬 메모리와 비교해 메모리 접근 시간이 증가하는 단점을 가지고 있다.
데이터를 책으로 비유하자면 기존 시스템은 집에 해당하는 CPU 크기의 제한으로 서재(메모리 용량)를 무한정 늘릴 수 없어, 보관할 수 있는 책 개수에 제한이 있는 것이다. 이에 압축 방식은 책의 내용을 압축하여 더 많은 책을 보관하는 방법이고, 스토리지 방식은 필요한 책들을 거리가 먼 도서관에서 구해오는 것과 비슷하다. CXL을 통한 메모리 확장은 집 옆에 창고를 지어 책을 보관하는 것으로 이해될 수 있다.
연구진이 개발한 AI 반도체(CXL-ANNS)는 CXL 스위치와 CXL 메모리 확장기를 사용해 근사 근접 이웃 탐색에서 필요한 모든 데이터를 메모리에 적재할 수 있어 정확도를 높이고 성능 감소를 없앴다. 또한 근사 근접 이웃 탐색의 특징을 활용해 데이터 근처 처리 기법과 지역성을 활용한 데이터 배치 기법으로 CXL-ANNS의 성능을 한 단계 향상했다. 이는 마치 창고 스스로가 필요한 책들의 내용을 요약하고 정리해 전달하고, 자주 보는 책들은 서재에 배치해 집과 창고를 오가는 시간을 줄이는 것과 유사하다.
연구진은 CXL-ANNS의 프로토타입을 자체 제작해 실효성을 확인하고, CXL-ANNS 성능을 기존 연구들과 비교했다. 마이크로소프트, 메타, 얀덱스 등의 글로벌 IT 기업에서 공개한 검색 데이터 셋을 사용한 근사 근접 이웃 탐색의 성능 비교에서 CXL-ANNS는 기존 연구들 대비 평균 111배 성능 향상이 있었다. 특히, 마이크로소프트의 상용화된 서비스에서 사용되는 방식과 비교하였을 때 92배의 성능 향상을 보여줬다.
정명수 교수는 "이번에 개발한 CXL-ANNS는 기존 검색 엔진의 문제였던 메모리 용량 제한 문제를 해결하고, CXL 기반의 메모리 확장이 실제 적용될 때 발생하는 메모리 접근 시간 지연 문제를 해결했다ˮ며, “제안하는 CXL 기반 메모리 확장과 데이터 근처 처리 가속의 패러다임은 검색 엔진뿐만 아니라 빅 데이터가 필요한 고성능 컴퓨팅, 유전자 탐색, 영상 처리 등의 다양한 분야에도 적용할 수 있다ˮ라고 말했다.
이번 연구는 미국 보스턴에서 오는 7월에 열릴 시스템 분야 최우수 학술대회인 유즈닉스 연례 회의 `USENIX Annual Technical Conference, 2023'에 ‘CXL-ANNS’이라는 이름으로 발표된 예정이다. (논문명: CXL-ANNS: Software-Hardware Collaborative Memory Disaggregation and Computation for Billion-Scale Approximate Nearest Neighbor Search)
한편 해당 연구는 파네시아(http://panmnesia.com)의 지원을 받아 진행됐다.
111배 빠른 검색엔진용 CXL 3.0 기반 AI반도체 세계 최초 개발
최근 각광받고 있는 이미지 검색, 데이터베이스, 추천 시스템, 광고 등의 서비스들은 마이크로소프트, 메타, 알리바바 등의 글로벌 IT 기업들에서 활발히 제공되고 있다. 하지만 실제 서비스에서 사용되는 데이터 셋은 크기가 매우 커, 많은 양의 메모리를 요구하여 기존 시스템에서는 추가할 수 있는 메모리 용량에 제한이 있어 이러한 요구사항을 만족할 수 없었다.
우리 대학 전기및전자공학부 정명수 교수 연구팀(컴퓨터 아키텍처 및 메모리 시스템 연구실)에서 대용량으로 메모리 확장이 가능한 컴퓨트 익스프레스 링크 3.0 기술(Compute eXpress Link, 이하 CXL)을 활용해 검색 엔진을 위한 AI 반도체를 세계 최초로 개발했다고 25일 밝혔다.
최근 검색 서비스에서 사용되는 알고리즘은 근사 근접 이웃 탐색(Approximate Nearest Neighbor Search, ANNS)으로 어떤 데이터든지 특징 벡터로 표현할 수 있다. 특징 벡터란 데이터가 가지는 특징들 각각을 숫자로 표현해 나열한 것으로, 이들 사이의 거리를 통해 우리는 데이터 간의 유사도를 구할 수 있다. 하지만 벡터 데이터 용량이 매우 커서 이를 압축해 메모리에 적재하는 압축 방식과 메모리보다 큰 용량과 느린 속도를 가지는 저장 장치를 사용하는 스토리지 방식(마이크로소프트에서 사용 중)이 사용되어 왔다. 하지만 이들 각각은 낮은 정확도와 성능을 가지는 문제가 있었다.
이에 정명수 교수 연구팀은 메모리 확장의 제한이라는 근본적인 문제를 해결하기 위해 CXL이라는 기술에 주목했다. CXL은 CPU-장치 간 연결을 위한 프로토콜로, 가속기 및 메모리 확장기의 고속 연결을 제공한다. 또한 CXL 스위치를 통해 여러 대의 메모리 확장기를 하나의 포트에 연결할 수 있는 확장성을 제공한다. 하지만 CXL을 통한 메모리 확장은 로컬 메모리와 비교해 메모리 접근 시간이 증가하는 단점을 가지고 있다.
데이터를 책으로 비유하자면 기존 시스템은 집에 해당하는 CPU 크기의 제한으로 서재(메모리 용량)를 무한정 늘릴 수 없어, 보관할 수 있는 책 개수에 제한이 있는 것이다. 이에 압축 방식은 책의 내용을 압축하여 더 많은 책을 보관하는 방법이고, 스토리지 방식은 필요한 책들을 거리가 먼 도서관에서 구해오는 것과 비슷하다. CXL을 통한 메모리 확장은 집 옆에 창고를 지어 책을 보관하는 것으로 이해될 수 있다.
연구진이 개발한 AI 반도체(CXL-ANNS)는 CXL 스위치와 CXL 메모리 확장기를 사용해 근사 근접 이웃 탐색에서 필요한 모든 데이터를 메모리에 적재할 수 있어 정확도를 높이고 성능 감소를 없앴다. 또한 근사 근접 이웃 탐색의 특징을 활용해 데이터 근처 처리 기법과 지역성을 활용한 데이터 배치 기법으로 CXL-ANNS의 성능을 한 단계 향상했다. 이는 마치 창고 스스로가 필요한 책들의 내용을 요약하고 정리해 전달하고, 자주 보는 책들은 서재에 배치해 집과 창고를 오가는 시간을 줄이는 것과 유사하다.
연구진은 CXL-ANNS의 프로토타입을 자체 제작해 실효성을 확인하고, CXL-ANNS 성능을 기존 연구들과 비교했다. 마이크로소프트, 메타, 얀덱스 등의 글로벌 IT 기업에서 공개한 검색 데이터 셋을 사용한 근사 근접 이웃 탐색의 성능 비교에서 CXL-ANNS는 기존 연구들 대비 평균 111배 성능 향상이 있었다. 특히, 마이크로소프트의 상용화된 서비스에서 사용되는 방식과 비교하였을 때 92배의 성능 향상을 보여줬다.
정명수 교수는 "이번에 개발한 CXL-ANNS는 기존 검색 엔진의 문제였던 메모리 용량 제한 문제를 해결하고, CXL 기반의 메모리 확장이 실제 적용될 때 발생하는 메모리 접근 시간 지연 문제를 해결했다ˮ며, “제안하는 CXL 기반 메모리 확장과 데이터 근처 처리 가속의 패러다임은 검색 엔진뿐만 아니라 빅 데이터가 필요한 고성능 컴퓨팅, 유전자 탐색, 영상 처리 등의 다양한 분야에도 적용할 수 있다ˮ라고 말했다.
이번 연구는 미국 보스턴에서 오는 7월에 열릴 시스템 분야 최우수 학술대회인 유즈닉스 연례 회의 `USENIX Annual Technical Conference, 2023'에 ‘CXL-ANNS’이라는 이름으로 발표된 예정이다. (논문명: CXL-ANNS: Software-Hardware Collaborative Memory Disaggregation and Computation for Billion-Scale Approximate Nearest Neighbor Search)
한편 해당 연구는 파네시아(http://panmnesia.com)의 지원을 받아 진행됐다.
2023.05.25
조회수 8455
-
 생생한 3차원 실사 이미지 구현하는 ‘메타브레인’ 개발
우리 대학 전기및전자공학부 유회준 교수 연구팀이 실사에 가까운 이미지를 렌더링할 수 있는 인공지능 기반 3D 렌더링을 모바일 기기에서 구현, 고속, 저전력 인공지능(AI: Artificial Intelligent) 반도체*인 메타브레인(MetaVRain)’을 세계 최초로 개발했다고 7일 밝혔다.
* 인공지능 반도체 : 인식·추론·학습·판단 등 인공지능 처리 기능을 탑재하고, 초지능·초저전력·초신뢰 기반의 최적화된 기술로 구현한 반도체
연구팀이 개발한 인공지능 반도체는 GPU로 구동되는 기존 레이 트레이싱 (ray-tracing)* 기반 3D 렌더링을 새로 제작된 AI 반도체 상에서 인공지능 기반 3차원으로 만들어, 기존의 막대한 비용이 들어가는 3차원 영상 캡쳐 스튜디오가 필요없게 되므로 3D 모델 제작에 드는 비용을 크게 줄이고, 사용되는 메모리를 180배 이상 줄일 수 있다. 특히 블렌더(Blender) 등의 복잡한 소프트웨어를 사용하던 기존 3D 그래픽 편집과 디자인을 간단한 인공지능 학습만으로 대체하여, 일반인도 손쉽게 원하는 스타일을 입히고 편집할 수 있다는 장점이 있다.
*레이 트레이싱 (ray-tracing): 광원, 물체의 형태, 질감에 따라 바뀌는 모든 광선의 궤적을 추적함으로써 실사에 가까운 이미지를 얻도록 하는 기술
한동현 박사과정이 제1 저자로 참여한 이번 연구는 지난 2월 18일부터 22일까지 전 세계 반도체 연구자들이 미국 샌프란시스코에 모여 개최한 국제고체회로설계학회(ISSCC)에서 발표됐다. (논문번호 2.7, 논문명: 메타브레인: A 133mW Real-time Hyper-realistic 3D NeRF Processor with 1D-2D Hybrid Neural Engines for Metaverse on Mobile Devices (저자: 한동현, 류준하, 김상엽, 김상진, 유회준))
유 교수팀은 인공지능을 통해 3D 렌더링을 구현할 때 발생하는 비효율적인 연산들을 발견하고 이를 줄이기 위해 사람의 시각적 인식 방식을 결합한 새로운 컨셉의 반도체를 개발했다. 사람은 사물을 기억할 때, 대략적인 윤곽에서 시작하여, 점점 그 형태를 구체화하는 과정과 바로 직전에 보았던 물체라면 이를 토대로 현재의 물체가 어떻게 생겼는지 바로 추측하는 인지능을 가지고 있다. 이러한 사람의 인지 과정을 모방하여, 새롭게 개발한 반도체는 저해상도 복셀을 통해 미리 사물의 대략적인 형태를 파악하고, 과거 렌더링했던 결과를 토대로, 현재 렌더링할 때 필요한 연산량을 최소화하는 연산 방식을 채택하였다.
유 교수팀이 개발한 메타브레인은 사람의 시각적 인식 과정을 모방한 하드웨어 아키텍처뿐만 아니라 최첨단 CMOS 칩을 함께 개발하여, 세계 최고의 성능을 달성하였다. 메타브레인은 인공지능 기반 3D 렌더링 기술에 최적화되어, 최대 100 FPS 이상의 렌더링 속도를 달성하였으며, 이는 기존 GPU보다 911배 빠른 속도다. 뿐만아니라, 1개 영상화면 처리 당 소모에너지를 나타내는 에너지효율 역시 GPU 대비 26,400배 높인 연구 결과로 VR/AR 헤드셋, 모바일 기기에서도 인공지능 기반 실시간 렌더링의 가능성을 열었다.
연구팀은 메타브레인의 활용 예시를 보여주고자, 스마트 3D 렌더링 응용시스템을 함께 개발하였으며, 사용자가 선호하는 스타일에 맞춰, 3D 모델의 스타일을 바꾸는 예제를 보여주었다. 인공지능에게 원하는 스타일의 이미지를 주고 재학습만 수행하면 되기 때문에, 복잡한 소프트웨어의 도움 없이도 손쉽게 3D 모델의 스타일을 손쉽게 바꿀 수 있다. 유 교수팀이 구현한 응용시스템의 예시 이외에도, 사용자의 얼굴을 본떠 만든 실제에 가까운 3D 아바타를 만들거나, 각종 구조물들의 3D 모델을 만들고 영화 제작 환경에 맞춰 날씨를 바꾸는 등 다양한 응용 예시가 가능할 것으로 기대된다.
연구팀은 메타브레인을 시작으로, 앞으로의 3D 그래픽스 분야 역시 인공지능으로 대체되기 시작할 것으로 기대한다며, 인공지능과 3D 그래픽스의 결합은 메타버스 실현을 위한 큰 기술적 혁신이라는 점을 밝혔다.
연구를 주도한 KAIST 전기및전자공학부 유회준 교수는 “현재 3D 그래픽스는 사람이 사물을 어떻게 보고 있는지가 아니라, 사물이 어떻게 생겼는지를 묘사하는데 집중하고 있다”라며 “이번 연구는 인공지능이 사람의 공간 인지 능력을 모방하여 사람이 사물을 인식하고 표현하는 방법을 차용함으로써 효율적인 3D 그래픽스를 가능케 한 연구”라고 본 연구의 의의를 밝혔다. 또한 “메타버스의 실현은 본 연구에서 보인 것처럼 인공지능 기술의 혁신과 인공지능 반도체의 혁신이 함께 이루어질 것”이라 미래를 전망하였다.
데모 동영상 유튜브 주소: https://www.youtube.com/watch?v=m-aqnZhALv0
생생한 3차원 실사 이미지 구현하는 ‘메타브레인’ 개발
우리 대학 전기및전자공학부 유회준 교수 연구팀이 실사에 가까운 이미지를 렌더링할 수 있는 인공지능 기반 3D 렌더링을 모바일 기기에서 구현, 고속, 저전력 인공지능(AI: Artificial Intelligent) 반도체*인 메타브레인(MetaVRain)’을 세계 최초로 개발했다고 7일 밝혔다.
* 인공지능 반도체 : 인식·추론·학습·판단 등 인공지능 처리 기능을 탑재하고, 초지능·초저전력·초신뢰 기반의 최적화된 기술로 구현한 반도체
연구팀이 개발한 인공지능 반도체는 GPU로 구동되는 기존 레이 트레이싱 (ray-tracing)* 기반 3D 렌더링을 새로 제작된 AI 반도체 상에서 인공지능 기반 3차원으로 만들어, 기존의 막대한 비용이 들어가는 3차원 영상 캡쳐 스튜디오가 필요없게 되므로 3D 모델 제작에 드는 비용을 크게 줄이고, 사용되는 메모리를 180배 이상 줄일 수 있다. 특히 블렌더(Blender) 등의 복잡한 소프트웨어를 사용하던 기존 3D 그래픽 편집과 디자인을 간단한 인공지능 학습만으로 대체하여, 일반인도 손쉽게 원하는 스타일을 입히고 편집할 수 있다는 장점이 있다.
*레이 트레이싱 (ray-tracing): 광원, 물체의 형태, 질감에 따라 바뀌는 모든 광선의 궤적을 추적함으로써 실사에 가까운 이미지를 얻도록 하는 기술
한동현 박사과정이 제1 저자로 참여한 이번 연구는 지난 2월 18일부터 22일까지 전 세계 반도체 연구자들이 미국 샌프란시스코에 모여 개최한 국제고체회로설계학회(ISSCC)에서 발표됐다. (논문번호 2.7, 논문명: 메타브레인: A 133mW Real-time Hyper-realistic 3D NeRF Processor with 1D-2D Hybrid Neural Engines for Metaverse on Mobile Devices (저자: 한동현, 류준하, 김상엽, 김상진, 유회준))
유 교수팀은 인공지능을 통해 3D 렌더링을 구현할 때 발생하는 비효율적인 연산들을 발견하고 이를 줄이기 위해 사람의 시각적 인식 방식을 결합한 새로운 컨셉의 반도체를 개발했다. 사람은 사물을 기억할 때, 대략적인 윤곽에서 시작하여, 점점 그 형태를 구체화하는 과정과 바로 직전에 보았던 물체라면 이를 토대로 현재의 물체가 어떻게 생겼는지 바로 추측하는 인지능을 가지고 있다. 이러한 사람의 인지 과정을 모방하여, 새롭게 개발한 반도체는 저해상도 복셀을 통해 미리 사물의 대략적인 형태를 파악하고, 과거 렌더링했던 결과를 토대로, 현재 렌더링할 때 필요한 연산량을 최소화하는 연산 방식을 채택하였다.
유 교수팀이 개발한 메타브레인은 사람의 시각적 인식 과정을 모방한 하드웨어 아키텍처뿐만 아니라 최첨단 CMOS 칩을 함께 개발하여, 세계 최고의 성능을 달성하였다. 메타브레인은 인공지능 기반 3D 렌더링 기술에 최적화되어, 최대 100 FPS 이상의 렌더링 속도를 달성하였으며, 이는 기존 GPU보다 911배 빠른 속도다. 뿐만아니라, 1개 영상화면 처리 당 소모에너지를 나타내는 에너지효율 역시 GPU 대비 26,400배 높인 연구 결과로 VR/AR 헤드셋, 모바일 기기에서도 인공지능 기반 실시간 렌더링의 가능성을 열었다.
연구팀은 메타브레인의 활용 예시를 보여주고자, 스마트 3D 렌더링 응용시스템을 함께 개발하였으며, 사용자가 선호하는 스타일에 맞춰, 3D 모델의 스타일을 바꾸는 예제를 보여주었다. 인공지능에게 원하는 스타일의 이미지를 주고 재학습만 수행하면 되기 때문에, 복잡한 소프트웨어의 도움 없이도 손쉽게 3D 모델의 스타일을 손쉽게 바꿀 수 있다. 유 교수팀이 구현한 응용시스템의 예시 이외에도, 사용자의 얼굴을 본떠 만든 실제에 가까운 3D 아바타를 만들거나, 각종 구조물들의 3D 모델을 만들고 영화 제작 환경에 맞춰 날씨를 바꾸는 등 다양한 응용 예시가 가능할 것으로 기대된다.
연구팀은 메타브레인을 시작으로, 앞으로의 3D 그래픽스 분야 역시 인공지능으로 대체되기 시작할 것으로 기대한다며, 인공지능과 3D 그래픽스의 결합은 메타버스 실현을 위한 큰 기술적 혁신이라는 점을 밝혔다.
연구를 주도한 KAIST 전기및전자공학부 유회준 교수는 “현재 3D 그래픽스는 사람이 사물을 어떻게 보고 있는지가 아니라, 사물이 어떻게 생겼는지를 묘사하는데 집중하고 있다”라며 “이번 연구는 인공지능이 사람의 공간 인지 능력을 모방하여 사람이 사물을 인식하고 표현하는 방법을 차용함으로써 효율적인 3D 그래픽스를 가능케 한 연구”라고 본 연구의 의의를 밝혔다. 또한 “메타버스의 실현은 본 연구에서 보인 것처럼 인공지능 기술의 혁신과 인공지능 반도체의 혁신이 함께 이루어질 것”이라 미래를 전망하였다.
데모 동영상 유튜브 주소: https://www.youtube.com/watch?v=m-aqnZhALv0
2023.03.07
조회수 8774
-
 이성주, 신진우 교수팀, 스스로 새로운 환경 적응하는 인공지능 기술 개발
우리 대학 전기및전자공학부 이성주 교수와 AI대학원 신진우 교수 연구팀이 공동연구를 통해 스스로 환경변화에 적응하는 테스트타임 적응 인공지능 기술을 개발했다고 밝혔다.
해당 연구는 “NOTE: Robust Continual Test-time Adaptation Against Temporal Correlation”라는 제목으로 인공지능 분야 최고권위 국제학술대회 ‘신경정보처리시스템학회(NeurIPS) 2022'에서12월 발표될 예정이다.
이성주 교수와 신진우 교수 공동 연구팀이 스스로 새로운 환경에 적응하는 “테스트타임 적응 (Test-Time Adaptation)” 인공지능 기술을 개발하였다. 연구팀이 제안한 알고리즘은 기존의 최고 성능 알고리즘보다 평균 11% 향상된 정확도를 보였다.
기계학습 모델들의 한계점은 학습했던 데이터와 다른 분포의 데이터에 적용되면 성능이 급격히 하락한다는 것이다. 이를 푸는 여러 방법 중에서 데이터를 미리 수집할 필요없이 모델이 스스로 테스트 데이터를 분석하여 변하는 환경에 적응하고 성능을 향상시키는 기술인 테스트타임 도메인 적응 (Test-Time Adaptation) 방법이 최근 산학계에서 크게 각광을 받고 있었다.
연구팀은 기존의 테스트타임 도메인 적응 기술들이 모두 데이터가 이상적인 균일분포를 따른다는 가정을 한다는 문제점에 착안했다. 실제 데이터는 환경 변화나 시간 변화에 따라 데이터 분포가 변하거나 비균일분포의 데이터에 대해서는 기존 기술을 동작하지 않는다. 하지만 연구팀이 제시한 “NOTE” 기술은 비균일분포의 데이터에서도 기존 최대 성능 알고리즘 보다 평균 11%만큼 향상된 정확도를 보였다.
이성주 교수 연구팀과 신진우 교수 연구팀의 공동연구로, 공태식 박사과정이 제1저자로 연구를 이끌었고, 정종헌 박사과정, 김태원 학사과정, 김예원 석사과정이 공동 저자로 기여하였다.
이성주 교수와 신진우 교수는 ”테스트타임 도메인 적응은 인공지능이 스스로 환경 변화에 적응하여 성능을 향상시키는 기술로, 활용도가 무궁무진하다. 이번에 발표될 NOTE 기술은 실제 데이터 분포에서 성능향상을 보인 최초의 기술이고 자율주행, 인공지능 의료, 모바일 헬스케어 등 다양한 분야에 적용이 가능할 것으로 기대된다.” 라고 밝혔다.
이 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원 (No. NRF-2020R1A2C1004062)과 방위사업청과 국방과학연구소의 지원(UD190031RD)으로 한국과학기술원 미래 국방 인공지능 특화연구센터에서 수행된 연구이다.
이성주, 신진우 교수팀, 스스로 새로운 환경 적응하는 인공지능 기술 개발
우리 대학 전기및전자공학부 이성주 교수와 AI대학원 신진우 교수 연구팀이 공동연구를 통해 스스로 환경변화에 적응하는 테스트타임 적응 인공지능 기술을 개발했다고 밝혔다.
해당 연구는 “NOTE: Robust Continual Test-time Adaptation Against Temporal Correlation”라는 제목으로 인공지능 분야 최고권위 국제학술대회 ‘신경정보처리시스템학회(NeurIPS) 2022'에서12월 발표될 예정이다.
이성주 교수와 신진우 교수 공동 연구팀이 스스로 새로운 환경에 적응하는 “테스트타임 적응 (Test-Time Adaptation)” 인공지능 기술을 개발하였다. 연구팀이 제안한 알고리즘은 기존의 최고 성능 알고리즘보다 평균 11% 향상된 정확도를 보였다.
기계학습 모델들의 한계점은 학습했던 데이터와 다른 분포의 데이터에 적용되면 성능이 급격히 하락한다는 것이다. 이를 푸는 여러 방법 중에서 데이터를 미리 수집할 필요없이 모델이 스스로 테스트 데이터를 분석하여 변하는 환경에 적응하고 성능을 향상시키는 기술인 테스트타임 도메인 적응 (Test-Time Adaptation) 방법이 최근 산학계에서 크게 각광을 받고 있었다.
연구팀은 기존의 테스트타임 도메인 적응 기술들이 모두 데이터가 이상적인 균일분포를 따른다는 가정을 한다는 문제점에 착안했다. 실제 데이터는 환경 변화나 시간 변화에 따라 데이터 분포가 변하거나 비균일분포의 데이터에 대해서는 기존 기술을 동작하지 않는다. 하지만 연구팀이 제시한 “NOTE” 기술은 비균일분포의 데이터에서도 기존 최대 성능 알고리즘 보다 평균 11%만큼 향상된 정확도를 보였다.
이성주 교수 연구팀과 신진우 교수 연구팀의 공동연구로, 공태식 박사과정이 제1저자로 연구를 이끌었고, 정종헌 박사과정, 김태원 학사과정, 김예원 석사과정이 공동 저자로 기여하였다.
이성주 교수와 신진우 교수는 ”테스트타임 도메인 적응은 인공지능이 스스로 환경 변화에 적응하여 성능을 향상시키는 기술로, 활용도가 무궁무진하다. 이번에 발표될 NOTE 기술은 실제 데이터 분포에서 성능향상을 보인 최초의 기술이고 자율주행, 인공지능 의료, 모바일 헬스케어 등 다양한 분야에 적용이 가능할 것으로 기대된다.” 라고 밝혔다.
이 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원 (No. NRF-2020R1A2C1004062)과 방위사업청과 국방과학연구소의 지원(UD190031RD)으로 한국과학기술원 미래 국방 인공지능 특화연구센터에서 수행된 연구이다.
2022.10.21
조회수 10538
-
 카이캐치(KaiCatch), 악성 동영상 위변조 탐지 기술 개발
우리 대학 전산학부 이흥규 명예교수 연구팀이 KAIST 창업기업인 ㈜디지탈이노텍의 후원으로 악성 위변조에 활용되는 프레임 업 변환, 보간법에 의해 생성된 프레임, 영상내 위변조 영역 등을 탐지하는 동영상 위변조 탐지 기술을 개발했다.
위변조 분야 최상위 저명 논문지인 Forensic Science International 11월호에 논문으로도 발표했다.
CCTV의 대량 보급과 함께 동영상은 수많은 분쟁시 주요 증거물로 사용되고 있다. 그러나 동영상에 대한 편집 도구 기술과 인공지능 기술 발전과 함께 동영상의 편집, 프레임 삭제 및 추가 등의 위변조를 포함하여 프레임 업 변환 이라는 기술을 사용하여 위변조 동영상을 고품질 영상으로 변환함으로써 위변조 동영상을 원본과 유사하게 변환함으로써 위변조 탐지를 더욱 어렵게 하는 악성 변조 기술 등도 등장하고 있다.
이번 연구에서는 동영상내 특정 영역들의 편집 변조를 포함하여 프레임 추가, 삭제, 프레임률 변환 탐지를 포함하여 공간정보와 시간정보를 연속적으로 활용하는 프레임-업 변환을 탐지하기 위해 프레임-업 특징들을 추출하는 4개 유형의 네트워크블럭들과 보팅(voting) 기능을 채택한 프레임-업 탐지 뉴럴 네트워크를 제시하였다.
개발된 기술은 특히 동영상의 극히 작은 영역들의 정보를 사용하여 무결성 여부를 판독하기 때문에 동영상 위변조 탐지를 고속으로 수행할 수 있어 기존 기술들과 비교하여 기술의 유용성과 실용성이 매우 뛰어나다.
이번 연구는 KAIST 윤민석 박사, ㈜네이버웹튠AI의 남승훈 박사 등이 참여하였으며 KAIST에서 위변조를 잡아낸다는 의미인 카이캐치(KaiCatch) 위변조 탐지 소프트웨어 기능을 동영상으로도 크게 확장 했다는 점에서 그 의미가 있다.
개발된 기술은 영상 위변조 분야 최상위 저명 논문지인 Forensic Science International 2022년 11월호(Vol 340)에 ‘Frame-rate Up-conversion Detection based on Convolutional Neural Network for Learning Spatiotemporal Features’ 논문으로 발표 되었다. 본 연구는 한국연구재단 창의도전연구기반지원사업과 KAIST 창업기업인 ㈜디지탈이노텍의 후원으로 수행하였다.
카이캐치(KaiCatch), 악성 동영상 위변조 탐지 기술 개발
우리 대학 전산학부 이흥규 명예교수 연구팀이 KAIST 창업기업인 ㈜디지탈이노텍의 후원으로 악성 위변조에 활용되는 프레임 업 변환, 보간법에 의해 생성된 프레임, 영상내 위변조 영역 등을 탐지하는 동영상 위변조 탐지 기술을 개발했다.
위변조 분야 최상위 저명 논문지인 Forensic Science International 11월호에 논문으로도 발표했다.
CCTV의 대량 보급과 함께 동영상은 수많은 분쟁시 주요 증거물로 사용되고 있다. 그러나 동영상에 대한 편집 도구 기술과 인공지능 기술 발전과 함께 동영상의 편집, 프레임 삭제 및 추가 등의 위변조를 포함하여 프레임 업 변환 이라는 기술을 사용하여 위변조 동영상을 고품질 영상으로 변환함으로써 위변조 동영상을 원본과 유사하게 변환함으로써 위변조 탐지를 더욱 어렵게 하는 악성 변조 기술 등도 등장하고 있다.
이번 연구에서는 동영상내 특정 영역들의 편집 변조를 포함하여 프레임 추가, 삭제, 프레임률 변환 탐지를 포함하여 공간정보와 시간정보를 연속적으로 활용하는 프레임-업 변환을 탐지하기 위해 프레임-업 특징들을 추출하는 4개 유형의 네트워크블럭들과 보팅(voting) 기능을 채택한 프레임-업 탐지 뉴럴 네트워크를 제시하였다.
개발된 기술은 특히 동영상의 극히 작은 영역들의 정보를 사용하여 무결성 여부를 판독하기 때문에 동영상 위변조 탐지를 고속으로 수행할 수 있어 기존 기술들과 비교하여 기술의 유용성과 실용성이 매우 뛰어나다.
이번 연구는 KAIST 윤민석 박사, ㈜네이버웹튠AI의 남승훈 박사 등이 참여하였으며 KAIST에서 위변조를 잡아낸다는 의미인 카이캐치(KaiCatch) 위변조 탐지 소프트웨어 기능을 동영상으로도 크게 확장 했다는 점에서 그 의미가 있다.
개발된 기술은 영상 위변조 분야 최상위 저명 논문지인 Forensic Science International 2022년 11월호(Vol 340)에 ‘Frame-rate Up-conversion Detection based on Convolutional Neural Network for Learning Spatiotemporal Features’ 논문으로 발표 되었다. 본 연구는 한국연구재단 창의도전연구기반지원사업과 KAIST 창업기업인 ㈜디지탈이노텍의 후원으로 수행하였다.
2022.10.20
조회수 10838
-
 정밀한 시각적 판단을 추론한 새로운 인공지능 가속칩 개발
우리 대학 전기및전자공학부 윤찬현, 김주영 교수 연구팀이 설명 가능한 인공지능(eXplainable AI, XAI) 기법을 처리하기 위한 노이즈(잡음)에 강한 다중 피라미드 활성화 맵 기반 주의집중 구조가 탑재된 인공지능 칩을 설계하고, 삼성전자 DS부문의 지원으로 설명가능 뉴로프로세싱 유닛(이하 EPU, Explainable neuro-Processing Unit)을 개발했다고 24일 밝혔다.
설명가능 인공지능이란 사람이 이해할 수 있고 신뢰할 수 있는 설명을 제공할 수 있는 인공지능 기법이다. 기존의 수학적 알고리즘으로 학습되는 인공지능은 학습예제에 편향되어 신뢰할 수 없거나, 수천억개의 매개변수를 사람이 이해할 수 없다는 문제점을 해결하기 위해, 왜 인공지능이 특정 결과를 추론했는지 판단근거를 설명할 수 있도록 개발되었다. 설명가능한 인공지능은 어떤 이유에 의해서 인공지능의 의사결정에 큰 영향을 주었는지 설명할 수 있다는 점에서 기존의 인공지능보다 정확성, 공정성, 신뢰성을 보장할 수 있다는 특징을 가진다.
공동연구팀은 다중 규모 및 다중물체의 특징 추출 구조인 피라미드형 신경망 구조에서 추론 결과에 영향을 주는 인공지능 내부의 신경층별 활성화되는 정도를 복합적으로 해석할 수 있는 인공지능 모델과 이를 가속처리 특화된 채널 방향 합성곱 연산 및 정확도를 유지하는 EPU칩을 구현했다.
다중 규모 및 다중물체 특징 추출에 특화된 피라미드형 인공지능 모델에서 설명 시각화 구현을 위해서는 추론 과정의 역방향으로 모든 합성곱 층별 활성화 맵에서 모델 파라미터의 변화도를 추출할 수 있는 구조가 요구된다.
그러나 역전파 계산 과정은 기존의 추론처리 가속을 위한 인공지능 칩 설계와 달리 이전 파라미터 및 상태를 기억해야 하며 이는 한정된 온 칩 메모리 크기 및 인공지능 모델 전체를 특정한 용도에 맞게 주문 제작(ASIC; Application Specific Integrated Circuit)해 구현하기에는 물리적 한계가 있다.
또한, 피라미드형 구조의 설명 가능한 인공지능 모델은 설명성 보장을 위한 N개 층의 활성화 맵으로부터 기울기 기반의 클래스 활성 맵핑 시각화 처리 각각 필요해 복잡도를 높이는 문제가 있다. 그리고, 입력의 매우 작은 노이즈에도 클래스 활성화 맵핑 시각화 설명이 완전히 달라져 설명 가능한 인공지능 모델의 신뢰도 저하가 큰 문제점이었다.
전기및전자공학부 윤찬현 교수 연구팀은 문제해결을 위해(그림1 참조) 설명 가능한 인공지능의 다중 활성화 맵 고유의 특성 정보를 융합해 전역 주의 집중 맵을 생성하는 네트워크 구조와 입력 이미지 노이즈에 강건한 모델 생성을 위한 상호학습 방법을 개발해, 단일 활성화 맵 기반 주의집중 맵 생성 기술에 비해 설명성 지표를 최대 6배가량 높였다.
또한, 다중 스케일의 다양한 주의집중 맵들의 상호 보완적인 특성을 일원화된 주의집중 맵으로 정교하게 재구성함으로써 사람이 해석 가능한 수준의 정밀한 설명성을 제공할 수 있게 했다. 이번 연구 성과를 통해 위성 영상과 같이 객체 크기 변화가 큰 이미지 분석에서 인공지능 모델의 설명성을 크게 향상할 수 있을 것으로 기대된다고 연구팀 관계자는 설명했다.
전기및전자공학부 김주영 교수 연구팀은 제안된 설명 가능한 인공지능 모델을 가속하기 위해 기존 모델의 추론과 역전파 과정에 더해 활성화 맵 생성까지 처리할 수 있는 XAI 코어를 개발하고, 다양한 연산 태스크를 유연하게 분할해 동시에 처리할 수 있는 멀티 데이터 플로우 방식을 제안했다. 또한, 많은 0 값을 포함하는 활성화 맵의 특성을 활용해, 연속된 0을 건너뛸 수 있는 새로운 데이터 압축 포맷을 제안하고 이를 지원하는 가속 유닛을 개발해 최대 10배 이상의 활성화 맵을 칩 내부에서 처리할 수 있도록 했다.
연구팀이 개발한 EPU 칩은 광학 위성, 전천후 관측 영상레이더(Synthetic Aperture Radar) 위성 등 특수 목적과 고정밀 인공지능 영상처리시스템에 적용할 수 있으며, 저지연‧저전력으로 인공지능 시스템의 판단 근거에 대한 설명성을 획기적으로 높일 수 있을 것으로 기대된다. 연구팀은 EPU 칩 개발 후속 연구를 진행할 계획이다.
정밀한 시각적 판단을 추론한 새로운 인공지능 가속칩 개발
우리 대학 전기및전자공학부 윤찬현, 김주영 교수 연구팀이 설명 가능한 인공지능(eXplainable AI, XAI) 기법을 처리하기 위한 노이즈(잡음)에 강한 다중 피라미드 활성화 맵 기반 주의집중 구조가 탑재된 인공지능 칩을 설계하고, 삼성전자 DS부문의 지원으로 설명가능 뉴로프로세싱 유닛(이하 EPU, Explainable neuro-Processing Unit)을 개발했다고 24일 밝혔다.
설명가능 인공지능이란 사람이 이해할 수 있고 신뢰할 수 있는 설명을 제공할 수 있는 인공지능 기법이다. 기존의 수학적 알고리즘으로 학습되는 인공지능은 학습예제에 편향되어 신뢰할 수 없거나, 수천억개의 매개변수를 사람이 이해할 수 없다는 문제점을 해결하기 위해, 왜 인공지능이 특정 결과를 추론했는지 판단근거를 설명할 수 있도록 개발되었다. 설명가능한 인공지능은 어떤 이유에 의해서 인공지능의 의사결정에 큰 영향을 주었는지 설명할 수 있다는 점에서 기존의 인공지능보다 정확성, 공정성, 신뢰성을 보장할 수 있다는 특징을 가진다.
공동연구팀은 다중 규모 및 다중물체의 특징 추출 구조인 피라미드형 신경망 구조에서 추론 결과에 영향을 주는 인공지능 내부의 신경층별 활성화되는 정도를 복합적으로 해석할 수 있는 인공지능 모델과 이를 가속처리 특화된 채널 방향 합성곱 연산 및 정확도를 유지하는 EPU칩을 구현했다.
다중 규모 및 다중물체 특징 추출에 특화된 피라미드형 인공지능 모델에서 설명 시각화 구현을 위해서는 추론 과정의 역방향으로 모든 합성곱 층별 활성화 맵에서 모델 파라미터의 변화도를 추출할 수 있는 구조가 요구된다.
그러나 역전파 계산 과정은 기존의 추론처리 가속을 위한 인공지능 칩 설계와 달리 이전 파라미터 및 상태를 기억해야 하며 이는 한정된 온 칩 메모리 크기 및 인공지능 모델 전체를 특정한 용도에 맞게 주문 제작(ASIC; Application Specific Integrated Circuit)해 구현하기에는 물리적 한계가 있다.
또한, 피라미드형 구조의 설명 가능한 인공지능 모델은 설명성 보장을 위한 N개 층의 활성화 맵으로부터 기울기 기반의 클래스 활성 맵핑 시각화 처리 각각 필요해 복잡도를 높이는 문제가 있다. 그리고, 입력의 매우 작은 노이즈에도 클래스 활성화 맵핑 시각화 설명이 완전히 달라져 설명 가능한 인공지능 모델의 신뢰도 저하가 큰 문제점이었다.
전기및전자공학부 윤찬현 교수 연구팀은 문제해결을 위해(그림1 참조) 설명 가능한 인공지능의 다중 활성화 맵 고유의 특성 정보를 융합해 전역 주의 집중 맵을 생성하는 네트워크 구조와 입력 이미지 노이즈에 강건한 모델 생성을 위한 상호학습 방법을 개발해, 단일 활성화 맵 기반 주의집중 맵 생성 기술에 비해 설명성 지표를 최대 6배가량 높였다.
또한, 다중 스케일의 다양한 주의집중 맵들의 상호 보완적인 특성을 일원화된 주의집중 맵으로 정교하게 재구성함으로써 사람이 해석 가능한 수준의 정밀한 설명성을 제공할 수 있게 했다. 이번 연구 성과를 통해 위성 영상과 같이 객체 크기 변화가 큰 이미지 분석에서 인공지능 모델의 설명성을 크게 향상할 수 있을 것으로 기대된다고 연구팀 관계자는 설명했다.
전기및전자공학부 김주영 교수 연구팀은 제안된 설명 가능한 인공지능 모델을 가속하기 위해 기존 모델의 추론과 역전파 과정에 더해 활성화 맵 생성까지 처리할 수 있는 XAI 코어를 개발하고, 다양한 연산 태스크를 유연하게 분할해 동시에 처리할 수 있는 멀티 데이터 플로우 방식을 제안했다. 또한, 많은 0 값을 포함하는 활성화 맵의 특성을 활용해, 연속된 0을 건너뛸 수 있는 새로운 데이터 압축 포맷을 제안하고 이를 지원하는 가속 유닛을 개발해 최대 10배 이상의 활성화 맵을 칩 내부에서 처리할 수 있도록 했다.
연구팀이 개발한 EPU 칩은 광학 위성, 전천후 관측 영상레이더(Synthetic Aperture Radar) 위성 등 특수 목적과 고정밀 인공지능 영상처리시스템에 적용할 수 있으며, 저지연‧저전력으로 인공지능 시스템의 판단 근거에 대한 설명성을 획기적으로 높일 수 있을 것으로 기대된다. 연구팀은 EPU 칩 개발 후속 연구를 진행할 계획이다.
2022.08.25
조회수 8942
-
 KAIST, 인공지능 반도체 생태계를 선도하다
인공지능 반도체(이하 AI 반도체)가 국가적인 전략기술로 두드러지면서 KAIST의 관련 성과도 주목받고 있다. 과학기술정보통신부는 지난해 2030년 세계 AI 반도체 시장 20% 점유를 목표로 인공지능 반도체 지원사업에 본격적으로 착수한 바 있다. 올해에는 산학연 논의를 거쳐 5년간 1조 200억 원을 투입하는 `인공지능 반도체 산업 성장 지원대책'으로 지원을 확대했다. 이에 따라 AI 반도체 전문가 양성을 위해 주요 대학들의 행보도 분주해졌다.
KAIST는 반도체와 인공지능 양대 핵심 분야에서 최상급의 교육, 연구 역량을 쌓아 왔다. 반도체 분야에서는 지난 17년 동안 메사추세츠 공과대학(이하 MIT), 스탠퍼드(Stanford)와 같은 세계적인 학교를 제치고 국제반도체회로학회(이하 ISSCC, International Solid State Circuit Conference)에서 대학 중 1위를 지켜 왔다는 점이 돋보인다. ISSCC는 1954년 설립된 반도체 집적회로 설계 분야 세계 최고 권위 학회다. 참가자 중 60% 이상이 삼성, 퀄컴, TSMC, 인텔을 비롯한 산업계 소속일만큼 산업적인 실용성을 중시해서 `반도체 설계 올림픽'이라는 별명도 있다.
KAIST는 ISSCC에서 채택 논문 수 기준 매년 전 세계 대학교 중 1~2위를 유지했다. 최근 17년간 평균 채택 논문 수를 살펴보면 압도적인 선두다. 해당 기간 채택된 KAIST의 논문은 평균 8.4편으로, 경쟁자인 MIT(4.6편)와 캘리포니아대학교 로스앤젤레스(UCLA)(3.6편)에 비해 두 배 가까운 성과다. 국내에서는 반도체 설계 분야 부동의 1위인 삼성에 이어 종합 2위 자리를 유지하고 있다. 그럴 뿐만 아니라 ISSCC와 쌍벽을 이루는 집적회로 분야 학술대회인 초고밀도집적회로학회에서도 KAIST는 2022년 전 세계 대학 중 1위를 기록했다.
KAIST의 연구진들이 반도체 산업 핵심 분야 전반에서 신기술을 발표해 연구의 질적인 수준도 높다. 전기및전자공학부 정명수 교수 연구팀은 고성능 저전력을 추구하는 현재 업계의 수요에 대응해 전력 공급 없이도 동작을 유지하는 컴퓨터를 개발했다. 소재 분야에서는 신소재공학과의 박병국 교수 연구팀이 기존의 메모리에 비해 동작 속도가 10배 이상 빠른 `스핀궤도토크 자성메모리' 소자를 개발해서 기존 `폰노이만 구조'의 한계를 극복하는 방안을 제시하기도 했다.
이처럼 현재 반도체 산업의 주요 과제에 솔루션을 제공하는 한편으로 미래의 새로운 반도체 분야를 선점하는 데 필요한 신기술 개발도 활발하다. 암호 및 비선형 연산 분야에서 차세대 컴퓨팅으로 주목받는 양자컴퓨팅 분야에서는 전기및전자공학부 김상현 교수 연구팀이 3차원 집적 기술을 세계 최초로 선보였다. 신경계의 원리를 활용해 인공지능 분야에서 발군의 성능을 보일 것으로 기대되는 뉴로모픽 컴퓨팅에서는 전기및전자공학부 최신현 교수 연구팀이 신경세포를 모사하는 차세대 멤리스터를 개발 중이다.
인공지능 분야에서도 비약적으로 성장했다. 인공지능 분야의 양대 세계 최고 권위 학회인 국제머신러닝학회(ICML)과 인공신경망학회(NeurIPS) 논문 수 기준으로 KAIST는 2020년 세계 6위, 아시아에서는 1위를 기록했다. KAIST의 순위는 2012년부터 꾸준히 우상향 그래프를 그려 8년만에 37위에서 6위로, 무려 31계단이나 도약했다. 2021년에는 인공지능 분야 톱 학회 11개에 발표된 한국 논문 중 약 40%에 달하는 129편이 KAIST에서 나왔다. KAIST의 이러한 활약에 힘입어 2021년 한국은 글로벌 인공지능 톱 학회 등재 논문 수 기준으로 미국, 중국, 영국, 캐나다, 독일에 이어 6위에 올랐다.
내용 면에서도 KAIST의 인공지능 연구는 최전선에 있다. 전기및전자공학부 유회준 교수 연구팀은 모바일기기에서 인공지능 실시간 학습을 구현해 에지 네트워크의 단점을 보완했다. 인공지능을 구현하려면 데이터 축적관 막대한 양의 연산이 필요한데, 이를 위해 고성능 서버가 방대한 연산을 담당하고 사용자 단말은 데이터 수집과 간단한 연산만 하는 `에지 네트워크'가 사용된다. 유 교수의 연구는 사용자 단말에 학습 능력을 부여함으로써 인공지능의 처리 속도와 성능을 크게 높일 수 있다.
지난 6월에는 전산학부 김민수 교수 연구팀이 초대규모 인공지능 모델 처리에 꼭 필요한 솔루션을 제시했다. 연구팀이 개발한 초대규모 기계학습 시스템은 현재 업계에서 주로 사용되는 구글의 텐서플로우(Tensorflow)나 IBM의 시스템DS 대비 최대 8.8배나 빠른 속도를 달성할 수 있을 것으로 기대된다.
KAIST는 반도체와 인공지능이 결합된 AI 반도체 분야에서도 주목할만한 성과를 내고 있다. 2020년 전기및전자공학부 유민수 교수 연구팀은 세계 최초로 추천시스템에 최적화된 AI 반도체를 개발하는 데 성공했다. 인공지능 추천시스템은 방대한 콘텐츠와 사용자 정보를 다룬다는 특성상 범용 인공지능 시스템으로 운영하면 병목현상으로 성능에 한계가 있다. 유민수 교수팀은 `프로세싱-인-메모리(이하 PIM, Processing-In-Memory)' 기술을 기반으로 기존 시스템 대비 최대 21배 빠른 속도를 낼 수 있는 반도체를 개발했다. PIM은 처리할 데이터를 임시로 저장하기만 하던 `램'에서 연산까지 수행해 효율을 높이는 기술이다. PIM 기술이 본격적으로 상용화되면 메모리 분야에서 강세인 한국 기업의 AI 반도체 시장 경쟁력이 비약적으로 높아질 것으로 기대된다.
KAIST는 그간의 성과에 안주하지 않고 인공지능 및 반도체, 그리고 AI 반도체 분야 초격차를 유지하고자 다각적인 노력을 기울이고 있다. 1990년 국내 최초로 인공지능연구센터를 설립한 데 이어 2019년에는 김재철AI대학원을 개설해 전문인력을 양성 중이다. 2020년에는 인공지능과 반도체 연구를 융합해 ITRC 인공지능반도체시스템 연구센터가 출범했으며, 2021년에는 인공지능을 다양한 분야에 접목하는 `AI+X' 연구를 활성화하고자 김재철AI대학원과 별도로 AI 연구원을 설립했다.
KAIST는 이러한 노력으로 축적된 내적 역량을 바탕으로 네이버 등 기업과 공동연구센터를 설립하는 한편, 화성시와 같은 지자체와 협력해 동시다발적인 전문인력 양성에 나섰다. 지난 2021년에는 삼성전자와 함께 반도체시스템공학과 설립 협약을 체결하고 새로운 반도체 전문인력 교육과정을 준비하고 있다. 새로 설립되는 반도체시스템공학과는 2023년부터 매년 100명 내외의 신입생을 선발하고, 이들이 전문역량을 꽃피울 수 있도록 학생 전원에게 특별장학금을 지급할 예정이다. 또한 산업계와의 긴밀한 협력을 통해 삼성전자 견학과 인턴십, 공동 워크숍을 지원해 현장에 밀착한 교육을 제공할 예정이다.
KAIST는 국내 반도체 분야 박사 인력의 25%, 박사 출신 중견 및 벤처기업 CEO의 20%를 배출하며 한국 반도체 산업 생태계가 성장하는 데 중대한 공헌을 했다. 본격적으로 열린 AI 반도체 경쟁 체제를 앞두고 KAIST가 다시 산업 생태계의 구심점 역할을 할지 귀추가 주목된다.
KAIST, 인공지능 반도체 생태계를 선도하다
인공지능 반도체(이하 AI 반도체)가 국가적인 전략기술로 두드러지면서 KAIST의 관련 성과도 주목받고 있다. 과학기술정보통신부는 지난해 2030년 세계 AI 반도체 시장 20% 점유를 목표로 인공지능 반도체 지원사업에 본격적으로 착수한 바 있다. 올해에는 산학연 논의를 거쳐 5년간 1조 200억 원을 투입하는 `인공지능 반도체 산업 성장 지원대책'으로 지원을 확대했다. 이에 따라 AI 반도체 전문가 양성을 위해 주요 대학들의 행보도 분주해졌다.
KAIST는 반도체와 인공지능 양대 핵심 분야에서 최상급의 교육, 연구 역량을 쌓아 왔다. 반도체 분야에서는 지난 17년 동안 메사추세츠 공과대학(이하 MIT), 스탠퍼드(Stanford)와 같은 세계적인 학교를 제치고 국제반도체회로학회(이하 ISSCC, International Solid State Circuit Conference)에서 대학 중 1위를 지켜 왔다는 점이 돋보인다. ISSCC는 1954년 설립된 반도체 집적회로 설계 분야 세계 최고 권위 학회다. 참가자 중 60% 이상이 삼성, 퀄컴, TSMC, 인텔을 비롯한 산업계 소속일만큼 산업적인 실용성을 중시해서 `반도체 설계 올림픽'이라는 별명도 있다.
KAIST는 ISSCC에서 채택 논문 수 기준 매년 전 세계 대학교 중 1~2위를 유지했다. 최근 17년간 평균 채택 논문 수를 살펴보면 압도적인 선두다. 해당 기간 채택된 KAIST의 논문은 평균 8.4편으로, 경쟁자인 MIT(4.6편)와 캘리포니아대학교 로스앤젤레스(UCLA)(3.6편)에 비해 두 배 가까운 성과다. 국내에서는 반도체 설계 분야 부동의 1위인 삼성에 이어 종합 2위 자리를 유지하고 있다. 그럴 뿐만 아니라 ISSCC와 쌍벽을 이루는 집적회로 분야 학술대회인 초고밀도집적회로학회에서도 KAIST는 2022년 전 세계 대학 중 1위를 기록했다.
KAIST의 연구진들이 반도체 산업 핵심 분야 전반에서 신기술을 발표해 연구의 질적인 수준도 높다. 전기및전자공학부 정명수 교수 연구팀은 고성능 저전력을 추구하는 현재 업계의 수요에 대응해 전력 공급 없이도 동작을 유지하는 컴퓨터를 개발했다. 소재 분야에서는 신소재공학과의 박병국 교수 연구팀이 기존의 메모리에 비해 동작 속도가 10배 이상 빠른 `스핀궤도토크 자성메모리' 소자를 개발해서 기존 `폰노이만 구조'의 한계를 극복하는 방안을 제시하기도 했다.
이처럼 현재 반도체 산업의 주요 과제에 솔루션을 제공하는 한편으로 미래의 새로운 반도체 분야를 선점하는 데 필요한 신기술 개발도 활발하다. 암호 및 비선형 연산 분야에서 차세대 컴퓨팅으로 주목받는 양자컴퓨팅 분야에서는 전기및전자공학부 김상현 교수 연구팀이 3차원 집적 기술을 세계 최초로 선보였다. 신경계의 원리를 활용해 인공지능 분야에서 발군의 성능을 보일 것으로 기대되는 뉴로모픽 컴퓨팅에서는 전기및전자공학부 최신현 교수 연구팀이 신경세포를 모사하는 차세대 멤리스터를 개발 중이다.
인공지능 분야에서도 비약적으로 성장했다. 인공지능 분야의 양대 세계 최고 권위 학회인 국제머신러닝학회(ICML)과 인공신경망학회(NeurIPS) 논문 수 기준으로 KAIST는 2020년 세계 6위, 아시아에서는 1위를 기록했다. KAIST의 순위는 2012년부터 꾸준히 우상향 그래프를 그려 8년만에 37위에서 6위로, 무려 31계단이나 도약했다. 2021년에는 인공지능 분야 톱 학회 11개에 발표된 한국 논문 중 약 40%에 달하는 129편이 KAIST에서 나왔다. KAIST의 이러한 활약에 힘입어 2021년 한국은 글로벌 인공지능 톱 학회 등재 논문 수 기준으로 미국, 중국, 영국, 캐나다, 독일에 이어 6위에 올랐다.
내용 면에서도 KAIST의 인공지능 연구는 최전선에 있다. 전기및전자공학부 유회준 교수 연구팀은 모바일기기에서 인공지능 실시간 학습을 구현해 에지 네트워크의 단점을 보완했다. 인공지능을 구현하려면 데이터 축적관 막대한 양의 연산이 필요한데, 이를 위해 고성능 서버가 방대한 연산을 담당하고 사용자 단말은 데이터 수집과 간단한 연산만 하는 `에지 네트워크'가 사용된다. 유 교수의 연구는 사용자 단말에 학습 능력을 부여함으로써 인공지능의 처리 속도와 성능을 크게 높일 수 있다.
지난 6월에는 전산학부 김민수 교수 연구팀이 초대규모 인공지능 모델 처리에 꼭 필요한 솔루션을 제시했다. 연구팀이 개발한 초대규모 기계학습 시스템은 현재 업계에서 주로 사용되는 구글의 텐서플로우(Tensorflow)나 IBM의 시스템DS 대비 최대 8.8배나 빠른 속도를 달성할 수 있을 것으로 기대된다.
KAIST는 반도체와 인공지능이 결합된 AI 반도체 분야에서도 주목할만한 성과를 내고 있다. 2020년 전기및전자공학부 유민수 교수 연구팀은 세계 최초로 추천시스템에 최적화된 AI 반도체를 개발하는 데 성공했다. 인공지능 추천시스템은 방대한 콘텐츠와 사용자 정보를 다룬다는 특성상 범용 인공지능 시스템으로 운영하면 병목현상으로 성능에 한계가 있다. 유민수 교수팀은 `프로세싱-인-메모리(이하 PIM, Processing-In-Memory)' 기술을 기반으로 기존 시스템 대비 최대 21배 빠른 속도를 낼 수 있는 반도체를 개발했다. PIM은 처리할 데이터를 임시로 저장하기만 하던 `램'에서 연산까지 수행해 효율을 높이는 기술이다. PIM 기술이 본격적으로 상용화되면 메모리 분야에서 강세인 한국 기업의 AI 반도체 시장 경쟁력이 비약적으로 높아질 것으로 기대된다.
KAIST는 그간의 성과에 안주하지 않고 인공지능 및 반도체, 그리고 AI 반도체 분야 초격차를 유지하고자 다각적인 노력을 기울이고 있다. 1990년 국내 최초로 인공지능연구센터를 설립한 데 이어 2019년에는 김재철AI대학원을 개설해 전문인력을 양성 중이다. 2020년에는 인공지능과 반도체 연구를 융합해 ITRC 인공지능반도체시스템 연구센터가 출범했으며, 2021년에는 인공지능을 다양한 분야에 접목하는 `AI+X' 연구를 활성화하고자 김재철AI대학원과 별도로 AI 연구원을 설립했다.
KAIST는 이러한 노력으로 축적된 내적 역량을 바탕으로 네이버 등 기업과 공동연구센터를 설립하는 한편, 화성시와 같은 지자체와 협력해 동시다발적인 전문인력 양성에 나섰다. 지난 2021년에는 삼성전자와 함께 반도체시스템공학과 설립 협약을 체결하고 새로운 반도체 전문인력 교육과정을 준비하고 있다. 새로 설립되는 반도체시스템공학과는 2023년부터 매년 100명 내외의 신입생을 선발하고, 이들이 전문역량을 꽃피울 수 있도록 학생 전원에게 특별장학금을 지급할 예정이다. 또한 산업계와의 긴밀한 협력을 통해 삼성전자 견학과 인턴십, 공동 워크숍을 지원해 현장에 밀착한 교육을 제공할 예정이다.
KAIST는 국내 반도체 분야 박사 인력의 25%, 박사 출신 중견 및 벤처기업 CEO의 20%를 배출하며 한국 반도체 산업 생태계가 성장하는 데 중대한 공헌을 했다. 본격적으로 열린 AI 반도체 경쟁 체제를 앞두고 KAIST가 다시 산업 생태계의 구심점 역할을 할지 귀추가 주목된다.
2022.08.04
조회수 18559
-
 스마트폰 위 인공지능(AI) 연합학습 속도 4.5배 획기적 향상기법 개발
우리 대학 전기및전자공학부 이성주 교수 연구팀이 국제공동연구를 통해 다수의 모바일 기기 위에서 인공지능(AI) 모델을 학습할 수 있는 연합학습 기술의 학습 속도를 4.5배 가속할 수 있는 방법론을 개발했다고 2일 밝혔다.
이성주 교수 연구팀은 지난 6/27~7/1에 열린 세계컴퓨터연합회(ACM) 주최로 진행된 제20회 모바일 시스템, 어플리케이션, 및 서비스 국제학술대회(MobiSys, International Conference on Mobile Systems, Applications, and Services)에서 연합학습(Federated Learning)의 학습 속도 향상(4.5배 가속)을 위한 데이터 샘플 최적 선택 및 데드라인 조절 방법론을 발표했다. 이 학회는 2003년에 시작됐으며 모바일 시스템, 소프트웨어, 어플리케이션, 서비스를 위한 최신 연구를 소개하는 데 초점을 맞추고 있으며, 모바일 컴퓨팅 및 시스템 분야의 최우수 학회 중 하나로 오랫동안 주목받고 있다.
이번 논문(FedBalancer: Data and Pace Control for Efficient Federated Learning on Heterogeneous Clients)은 KAIST 전산학부 신재민 박사과정이 제1 저자로 참여했으며, 중국 칭화대학과의 국제협력으로 이루어진 성과다 (칭화대학교 위안춘 리(Yuanchun Li) 교수, 윤신 리우(Yunxin Liu) 교수 참여).
최근 구글에 의해 제안된 연합학습은 새로운 기계학습 기술로, 개인정보의 유출 없이 방대한 사용자 기기 위 데이터를 활용할 수 있게 하여 의료 인공지능 기술 등 새로운 인공지능 서비스를 개발할 수 있게 해 각광받고 있다. 연합학습은 구글을 비롯해 애플, 타오바오 등 세계적 빅테크 기업들이 널리 도입하고 있으나, 실제로는 인공지능 모델 학습이 사용자의 스마트폰 위에서 이뤄져, 기기에 과부하를 일으켜 배터리 소모, 성능 저하 등이 발생할 수 있는 우려를 안고 있다.
이성주 교수 연구팀은 연합학습에 참여하는 사용자 기기 위 데이터 샘플 각각의 학습 기여도 측정을 기반으로 최적의 샘플을 선택함으로써 연합학습 속도 향상을 달성했다. 또한, 샘플 선택으로 줄어든 학습 시간에 대응해, 연합학습 라운드의 데드라인 또한 최적으로 조절하는 기법을 제안해 모델 정확도의 저하 없이 학습 속도를 무려 4.5배 높였다. 이러한 방법론의 적용을 통해 연합학습으로 인한 사용자 스마트폰 과부하 문제를 최소화할 수 있을 것으로 기대된다.
이성주 교수는 "연합학습은 많은 세계적 기업들이 사용하는 중요한 기술이다ˮ며 "이번 연구 결과는 연합학습의 학습 속도를 향상하고 활용도를 높여 의미가 있으며, 컴퓨터 비전, 자연어 처리, 모바일 센서 데이터 등 다양한 응용에서 모두 좋은 성능을 보여, 빠른 파급효과를 기대한다ˮ라고 소감을 밝혔다.
한편 이 연구는 과학기술정보통신부의 재원으로 한국연구재단과 정보통신기술진흥센터의 지원을 받아 수행됐다.
스마트폰 위 인공지능(AI) 연합학습 속도 4.5배 획기적 향상기법 개발
우리 대학 전기및전자공학부 이성주 교수 연구팀이 국제공동연구를 통해 다수의 모바일 기기 위에서 인공지능(AI) 모델을 학습할 수 있는 연합학습 기술의 학습 속도를 4.5배 가속할 수 있는 방법론을 개발했다고 2일 밝혔다.
이성주 교수 연구팀은 지난 6/27~7/1에 열린 세계컴퓨터연합회(ACM) 주최로 진행된 제20회 모바일 시스템, 어플리케이션, 및 서비스 국제학술대회(MobiSys, International Conference on Mobile Systems, Applications, and Services)에서 연합학습(Federated Learning)의 학습 속도 향상(4.5배 가속)을 위한 데이터 샘플 최적 선택 및 데드라인 조절 방법론을 발표했다. 이 학회는 2003년에 시작됐으며 모바일 시스템, 소프트웨어, 어플리케이션, 서비스를 위한 최신 연구를 소개하는 데 초점을 맞추고 있으며, 모바일 컴퓨팅 및 시스템 분야의 최우수 학회 중 하나로 오랫동안 주목받고 있다.
이번 논문(FedBalancer: Data and Pace Control for Efficient Federated Learning on Heterogeneous Clients)은 KAIST 전산학부 신재민 박사과정이 제1 저자로 참여했으며, 중국 칭화대학과의 국제협력으로 이루어진 성과다 (칭화대학교 위안춘 리(Yuanchun Li) 교수, 윤신 리우(Yunxin Liu) 교수 참여).
최근 구글에 의해 제안된 연합학습은 새로운 기계학습 기술로, 개인정보의 유출 없이 방대한 사용자 기기 위 데이터를 활용할 수 있게 하여 의료 인공지능 기술 등 새로운 인공지능 서비스를 개발할 수 있게 해 각광받고 있다. 연합학습은 구글을 비롯해 애플, 타오바오 등 세계적 빅테크 기업들이 널리 도입하고 있으나, 실제로는 인공지능 모델 학습이 사용자의 스마트폰 위에서 이뤄져, 기기에 과부하를 일으켜 배터리 소모, 성능 저하 등이 발생할 수 있는 우려를 안고 있다.
이성주 교수 연구팀은 연합학습에 참여하는 사용자 기기 위 데이터 샘플 각각의 학습 기여도 측정을 기반으로 최적의 샘플을 선택함으로써 연합학습 속도 향상을 달성했다. 또한, 샘플 선택으로 줄어든 학습 시간에 대응해, 연합학습 라운드의 데드라인 또한 최적으로 조절하는 기법을 제안해 모델 정확도의 저하 없이 학습 속도를 무려 4.5배 높였다. 이러한 방법론의 적용을 통해 연합학습으로 인한 사용자 스마트폰 과부하 문제를 최소화할 수 있을 것으로 기대된다.
이성주 교수는 "연합학습은 많은 세계적 기업들이 사용하는 중요한 기술이다ˮ며 "이번 연구 결과는 연합학습의 학습 속도를 향상하고 활용도를 높여 의미가 있으며, 컴퓨터 비전, 자연어 처리, 모바일 센서 데이터 등 다양한 응용에서 모두 좋은 성능을 보여, 빠른 파급효과를 기대한다ˮ라고 소감을 밝혔다.
한편 이 연구는 과학기술정보통신부의 재원으로 한국연구재단과 정보통신기술진흥센터의 지원을 받아 수행됐다.
2022.08.02
조회수 12533
-
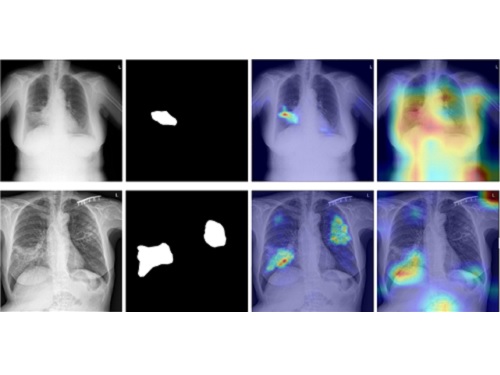 스스로 진화하는 흉부 엑스선 인공지능 진단기술 개발
우리 대학 김재철AI대학원 예종철 교수 연구팀이 서울대학교 병원, 서울 아산병원, 충남대학교 병원, 영남대학교 병원, 경북대학교 병원과의 공동연구를 통해 결핵, 기흉, 코로나-19 등의 흉부 엑스선 영상을 이용한 폐 질환의 자동 판독 능력을 스스로 향상할 수 있는 자기 진화형 인공지능 기술을 개발했다고 27일 밝혔다.
현재 사용되는 대부분의 의료 인공지능 기법은 지도학습 방식 (Supervised learning)으로서 인공지능 모델을 학습하기 위해서는 전문가에 의한 다량의 라벨이 필수적이나, 실제 임상 현장에서 전문가에 의해 라벨링 된 대규모의 데이터를 지속해서 얻는 것이 비용과 시간이 많이 들어 이러한 문제가 의료 인공지능 발전의 걸림돌이 돼왔다.
이러한 문제를 해결하기 위해, 예종철 교수팀은 병원 현장에서 영상의학과 전문의들이 영상 판독을 학습하는 과정과 유사하게, 자기 학습과 선생-학생 간의 지식전달 기법을 묘사한 지식 증류 기법을 활용한 자기 지도학습 및 자기 훈련 방식(Distillation for self-supervised and self-train learning, 이하 DISTL) 인공지능 알고리즘을 개발했다. 제안하는 인공지능 알고리즘은 적은 수의 라벨데이터만 갖고 초기 모델을 학습시키면 시간이 지남에 따라 축적되는 라벨 없는 데이터 자체만을 가지고 해당 모델이 스스로 성능을 향상해 나갈 수 있는 것을 보였다.
실제 의료 영상 분야에서 전문가들이 판독한 정제된 라벨 획득의 어려움은 영상 양식이나 작업과 관계없이 빈번하게 발생하는 문제점이고, 이러한 영상 전문의의 부족 현상은 저소득 국가들과 개발도상국과 같이 결핵과 같은 다양한 전염성 질환이 많이 발생하는 지역에 많다는 점을 고려할 때, 예 교수팀에서 개발한 인공지능 알고리즘은 해당 지역에서 인공지능 모델을 자기 진화시키는 방식으로 진단 정확도를 향상하는 데 큰 도움을 줄 것으로 기대된다.
예종철 교수는 “지도학습 방식으로 성능을 향상하기 위해서는 전문가 라벨을 지속해서 획득해야 하고, 비 지도학습 방식으로는 성능이 낮다는 문제점을 극복한 DISTL 모델은 영상 전문의들의 인공지능 학습을 위한 레이블 생성 비용과 수고를 줄이면서도 지도학습 성능을 뛰어넘었다는 점에서 의미가 있고, 다양한 영상 양식 및 작업에 활용할 수 있을 것으로 기대된다”라고 말했다.
예종철 교수 연구팀의 박상준 박사과정이 제1 저자로 참여한 이번 연구 결과는 국제 학술지 `네이처 커뮤니케이션스(Nature Communications)'에 7월 4일 자로 게재됐다.
한편 이번 연구는 중견연구자지원사업, 범부처전주기의료기기연구개발사업 및 한국과학기술원 중점연구소 사업등의 지원을 받아 수행됐다.
*논문명: Self-evolving vision transformer for chest X-ray diagnosis through knowledge distillation
논문 링크: https://www.nature.com/articles/s41467-022-31514-x
스스로 진화하는 흉부 엑스선 인공지능 진단기술 개발
우리 대학 김재철AI대학원 예종철 교수 연구팀이 서울대학교 병원, 서울 아산병원, 충남대학교 병원, 영남대학교 병원, 경북대학교 병원과의 공동연구를 통해 결핵, 기흉, 코로나-19 등의 흉부 엑스선 영상을 이용한 폐 질환의 자동 판독 능력을 스스로 향상할 수 있는 자기 진화형 인공지능 기술을 개발했다고 27일 밝혔다.
현재 사용되는 대부분의 의료 인공지능 기법은 지도학습 방식 (Supervised learning)으로서 인공지능 모델을 학습하기 위해서는 전문가에 의한 다량의 라벨이 필수적이나, 실제 임상 현장에서 전문가에 의해 라벨링 된 대규모의 데이터를 지속해서 얻는 것이 비용과 시간이 많이 들어 이러한 문제가 의료 인공지능 발전의 걸림돌이 돼왔다.
이러한 문제를 해결하기 위해, 예종철 교수팀은 병원 현장에서 영상의학과 전문의들이 영상 판독을 학습하는 과정과 유사하게, 자기 학습과 선생-학생 간의 지식전달 기법을 묘사한 지식 증류 기법을 활용한 자기 지도학습 및 자기 훈련 방식(Distillation for self-supervised and self-train learning, 이하 DISTL) 인공지능 알고리즘을 개발했다. 제안하는 인공지능 알고리즘은 적은 수의 라벨데이터만 갖고 초기 모델을 학습시키면 시간이 지남에 따라 축적되는 라벨 없는 데이터 자체만을 가지고 해당 모델이 스스로 성능을 향상해 나갈 수 있는 것을 보였다.
실제 의료 영상 분야에서 전문가들이 판독한 정제된 라벨 획득의 어려움은 영상 양식이나 작업과 관계없이 빈번하게 발생하는 문제점이고, 이러한 영상 전문의의 부족 현상은 저소득 국가들과 개발도상국과 같이 결핵과 같은 다양한 전염성 질환이 많이 발생하는 지역에 많다는 점을 고려할 때, 예 교수팀에서 개발한 인공지능 알고리즘은 해당 지역에서 인공지능 모델을 자기 진화시키는 방식으로 진단 정확도를 향상하는 데 큰 도움을 줄 것으로 기대된다.
예종철 교수는 “지도학습 방식으로 성능을 향상하기 위해서는 전문가 라벨을 지속해서 획득해야 하고, 비 지도학습 방식으로는 성능이 낮다는 문제점을 극복한 DISTL 모델은 영상 전문의들의 인공지능 학습을 위한 레이블 생성 비용과 수고를 줄이면서도 지도학습 성능을 뛰어넘었다는 점에서 의미가 있고, 다양한 영상 양식 및 작업에 활용할 수 있을 것으로 기대된다”라고 말했다.
예종철 교수 연구팀의 박상준 박사과정이 제1 저자로 참여한 이번 연구 결과는 국제 학술지 `네이처 커뮤니케이션스(Nature Communications)'에 7월 4일 자로 게재됐다.
한편 이번 연구는 중견연구자지원사업, 범부처전주기의료기기연구개발사업 및 한국과학기술원 중점연구소 사업등의 지원을 받아 수행됐다.
*논문명: Self-evolving vision transformer for chest X-ray diagnosis through knowledge distillation
논문 링크: https://www.nature.com/articles/s41467-022-31514-x
2022.07.27
조회수 10036