%EC%A0%84%EA%B8%B0%EB%B0%8F%EC%A0%84%EC%9E%90%EA%B3%B5%ED%95%99%EB%B6%80
-
 주변 빛에너지로 24시간 건강 모니터링이 가능하다고?
심박수, 혈중산소포화도, 땀 성분 분석 등 지속적인 건강 모니터링을 위한 의료용 웨어러블 기기의 소형화와 경량화는 여전히 큰 도전 과제다. 특히 광학 센서는 LED 구동과 무선 전송에 많은 전력을 소모해 무겁고 부피가 큰 배터리를 필요로 한다. 이런 한계를 극복하기 위해 우리 연구진은 주변 빛을 에너지원으로 활용하고, 전력 상황에 따라 최적화된 관리를 통해 24시간 연속 측정이 가능한 차세대 웨어러블 플랫폼을 개발했다.
우리 대학 전기및전자공학부 권경하 교수팀이 미국 노스웨스턴대학교 박찬호 박사팀과 공동연구를 통해, 주변 빛을 활용해 배터리 전력 부담을 줄인 적응형 무선 웨어러블 플랫폼을 개발했다고 30일 밝혔다.
의료용 웨어러블 기기의 배터리 문제를 해결하기 위해, 권경하 교수 연구팀은 주변의 자연광을 에너지원으로 활용하는 혁신적인 플랫폼을 개발했다. 이 플랫폼은 세 가지 상호 보완적인 빛 에너지 기술을 통합한 것이 특징이다.
첫 번째 핵심 기술인 ‘광 측정 방식(Photometric Method)’은 주변 광원의 세기에 따라 LED 밝기를 적응적으로 조절하는 기술이다. 주변 자연광과 LED 빛을 합쳐 일정한 총 조명량을 유지하되, 자연광이 강할 때는 LED를 어둡게, 자연광이 약할 때는 LED를 밝게 자동 조절한다.
기존 센서가 환경과 관계없이 LED를 일정하게 켜야 했다면, 이 기술은 주변 환경에 맞춰 LED 전력을 실시간으로 최적화할 수 있다. 실험 결과, 충분한 조명 환경에서 전력 소모를 86.22%나 줄였다.
두 번째는 ‘고효율 다접합 태양전지(Photovoltaic Method)’ 기술이다. 이는 단순한 태양광 발전을 넘어서 실내외 모든 환경의 빛을 전력으로 변환한다. 특히 적응형 전력 관리 시스템을 통해 주변 환경과 배터리 상태에 따라 11가지 서로 다른 전력 구성으로 자동 전환되어 최적의 에너지 효율을 달성한다.
세 번째 혁신 기술은 ‘축광/발광(Photoluminescent Method)’기술이다. 스트론튬 알루미네이트 미세입자*를 센서의 실리콘 캡슐화 구조에 혼합해, 낮 동안 주변 빛을 흡수해 저장했다가 어둠 속에서 서서히 방출한다. 이를 통해 태양광 500W/m²에 10분간 노출되면 완전한 어둠에서도 2.5분간 연속 측정이 가능하다.
*스트론튬 알루미네이트 미세입자: 야광페인트나 안전 표지판에 사용되는 형광체로, 빛을 흡수한 후 어둠 속에서 오랫동안 발광하는 축광 소재
이 세 가지 기술이 상호 보완적으로 작동해 밝은 환경에서는 첫 번째와 두 번째 방식이, 어두운 환경에서는 세 번째 방식이 추가로 지원하는 방식으로 24시간 연속 작동을 가능하게 한다.
연구팀은 이 플랫폼을 다양한 의료 센서에 적용해 실용성을 검증했다. 광용적맥파 측정 센서는 심박수와 혈중산소포화도를 실시간으로 모니터링해 심혈관 질환의 조기 발견을 가능하게 한다. 청색광 노출량 측정 센서는 피부 노화와 손상을 유발하는 블루라이트를 정확히 측정해 개인 맞춤형 피부 보호 가이드를 제공한다. 땀 분석 센서는 마이크로 유체 기술을 활용, 땀 속 염분, 포도당, pH를 동시에 분석해 탈수나 전해질 불균형을 실시간으로 감지할 수 있다.
추가적으로 센서 내 데이터 처리 기술을 도입해 무선 통신으로 인한 전력 소모도 대폭 줄였다. 기존에는 모든 원시 데이터를 외부로 전송해야 했지만, 이제는 센서 내부에서 필요한 결과만 계산해 전송함으로써 데이터 전송량을 400B/s에서 4B/s로 100배 감소시켰다.
연구팀은 성능 검증을 위해 건강한 성인 피험자를 대상으로 밝은 실내조명, 어두운 조명, 적외선 조명, 완전한 어둠 등 4가지 서로 다른 환경에서 테스트했다. 그 결과, 모든 조건에서 상용 의료기기와 동등한 측정 정확도를 보였다. 생쥐 모델을 이용한 저산소 상태 실험에서도 정확한 혈중산소포화도 측정이 가능함을 확인했다.
연구를 주도한 권경하 교수는 “이 기술을 활용해 24시간 연속 건강 모니터링이 가능해짐에 따라 의료 패러다임이 치료 중심에서 예방 중심으로 전환될 수 있을 것”이라며, “조기 진단을 통한 의료비 절감 효과와 함께 차세대 웨어러블 헬스케어 시장에서의 기술경쟁력 확보도 기대된다”라고 말했다.
이번 연구 결과는 인공지능반도체대학원 박도윤 박사과정 학생이 공동 제 1 저자로 국제 학술지 네이처 커뮤니케이션스(Nature Communications)에 7월 1일 발표됐다.
※논문명 : Adaptive Electronics for Photovoltaic, Photoluminescent and Photometric Methods in Power Harvesting for Wireless and Wearable Sensors;
※DOI: URL: https://www.nature.com/articles/s41467-025-60911-1
한편, 이번 연구는 한국연구재단 우수신진연구, 지역혁신 선도연구센터 과제, 과학기술정보통신부 정보통신기획평가원(IITP) 인공지능반도체대학원 과제, 그리고 BK FOUR 프로그램(Connected AI Education & Research Program for Industry and Society Innovation, KAIST EE)의 지원을 받아 수행됐다.
2025.07.31 조회수 759
주변 빛에너지로 24시간 건강 모니터링이 가능하다고?
심박수, 혈중산소포화도, 땀 성분 분석 등 지속적인 건강 모니터링을 위한 의료용 웨어러블 기기의 소형화와 경량화는 여전히 큰 도전 과제다. 특히 광학 센서는 LED 구동과 무선 전송에 많은 전력을 소모해 무겁고 부피가 큰 배터리를 필요로 한다. 이런 한계를 극복하기 위해 우리 연구진은 주변 빛을 에너지원으로 활용하고, 전력 상황에 따라 최적화된 관리를 통해 24시간 연속 측정이 가능한 차세대 웨어러블 플랫폼을 개발했다.
우리 대학 전기및전자공학부 권경하 교수팀이 미국 노스웨스턴대학교 박찬호 박사팀과 공동연구를 통해, 주변 빛을 활용해 배터리 전력 부담을 줄인 적응형 무선 웨어러블 플랫폼을 개발했다고 30일 밝혔다.
의료용 웨어러블 기기의 배터리 문제를 해결하기 위해, 권경하 교수 연구팀은 주변의 자연광을 에너지원으로 활용하는 혁신적인 플랫폼을 개발했다. 이 플랫폼은 세 가지 상호 보완적인 빛 에너지 기술을 통합한 것이 특징이다.
첫 번째 핵심 기술인 ‘광 측정 방식(Photometric Method)’은 주변 광원의 세기에 따라 LED 밝기를 적응적으로 조절하는 기술이다. 주변 자연광과 LED 빛을 합쳐 일정한 총 조명량을 유지하되, 자연광이 강할 때는 LED를 어둡게, 자연광이 약할 때는 LED를 밝게 자동 조절한다.
기존 센서가 환경과 관계없이 LED를 일정하게 켜야 했다면, 이 기술은 주변 환경에 맞춰 LED 전력을 실시간으로 최적화할 수 있다. 실험 결과, 충분한 조명 환경에서 전력 소모를 86.22%나 줄였다.
두 번째는 ‘고효율 다접합 태양전지(Photovoltaic Method)’ 기술이다. 이는 단순한 태양광 발전을 넘어서 실내외 모든 환경의 빛을 전력으로 변환한다. 특히 적응형 전력 관리 시스템을 통해 주변 환경과 배터리 상태에 따라 11가지 서로 다른 전력 구성으로 자동 전환되어 최적의 에너지 효율을 달성한다.
세 번째 혁신 기술은 ‘축광/발광(Photoluminescent Method)’기술이다. 스트론튬 알루미네이트 미세입자*를 센서의 실리콘 캡슐화 구조에 혼합해, 낮 동안 주변 빛을 흡수해 저장했다가 어둠 속에서 서서히 방출한다. 이를 통해 태양광 500W/m²에 10분간 노출되면 완전한 어둠에서도 2.5분간 연속 측정이 가능하다.
*스트론튬 알루미네이트 미세입자: 야광페인트나 안전 표지판에 사용되는 형광체로, 빛을 흡수한 후 어둠 속에서 오랫동안 발광하는 축광 소재
이 세 가지 기술이 상호 보완적으로 작동해 밝은 환경에서는 첫 번째와 두 번째 방식이, 어두운 환경에서는 세 번째 방식이 추가로 지원하는 방식으로 24시간 연속 작동을 가능하게 한다.
연구팀은 이 플랫폼을 다양한 의료 센서에 적용해 실용성을 검증했다. 광용적맥파 측정 센서는 심박수와 혈중산소포화도를 실시간으로 모니터링해 심혈관 질환의 조기 발견을 가능하게 한다. 청색광 노출량 측정 센서는 피부 노화와 손상을 유발하는 블루라이트를 정확히 측정해 개인 맞춤형 피부 보호 가이드를 제공한다. 땀 분석 센서는 마이크로 유체 기술을 활용, 땀 속 염분, 포도당, pH를 동시에 분석해 탈수나 전해질 불균형을 실시간으로 감지할 수 있다.
추가적으로 센서 내 데이터 처리 기술을 도입해 무선 통신으로 인한 전력 소모도 대폭 줄였다. 기존에는 모든 원시 데이터를 외부로 전송해야 했지만, 이제는 센서 내부에서 필요한 결과만 계산해 전송함으로써 데이터 전송량을 400B/s에서 4B/s로 100배 감소시켰다.
연구팀은 성능 검증을 위해 건강한 성인 피험자를 대상으로 밝은 실내조명, 어두운 조명, 적외선 조명, 완전한 어둠 등 4가지 서로 다른 환경에서 테스트했다. 그 결과, 모든 조건에서 상용 의료기기와 동등한 측정 정확도를 보였다. 생쥐 모델을 이용한 저산소 상태 실험에서도 정확한 혈중산소포화도 측정이 가능함을 확인했다.
연구를 주도한 권경하 교수는 “이 기술을 활용해 24시간 연속 건강 모니터링이 가능해짐에 따라 의료 패러다임이 치료 중심에서 예방 중심으로 전환될 수 있을 것”이라며, “조기 진단을 통한 의료비 절감 효과와 함께 차세대 웨어러블 헬스케어 시장에서의 기술경쟁력 확보도 기대된다”라고 말했다.
이번 연구 결과는 인공지능반도체대학원 박도윤 박사과정 학생이 공동 제 1 저자로 국제 학술지 네이처 커뮤니케이션스(Nature Communications)에 7월 1일 발표됐다.
※논문명 : Adaptive Electronics for Photovoltaic, Photoluminescent and Photometric Methods in Power Harvesting for Wireless and Wearable Sensors;
※DOI: URL: https://www.nature.com/articles/s41467-025-60911-1
한편, 이번 연구는 한국연구재단 우수신진연구, 지역혁신 선도연구센터 과제, 과학기술정보통신부 정보통신기획평가원(IITP) 인공지능반도체대학원 과제, 그리고 BK FOUR 프로그램(Connected AI Education & Research Program for Industry and Society Innovation, KAIST EE)의 지원을 받아 수행됐다.
2025.07.31 조회수 759 -
 단 하나의 패킷으로 스마트폰 마비시키는 보안 취약점 발견
스마트폰은 언제 어디서나 이동통신 네트워크에 연결돼 있어야 작동한다. 이러한 상시 연결성을 가능하게 하는 핵심 부품은 단말기 내부의 통신 모뎀(Baseband)이다. KAIST 연구진이 자체 개발한‘LLFuzz(Lower Layer Fuzz)’라는 테스트 프레임워크를 통해, 스마트폰 통신 모뎀 하위계층의 보안 취약점을 발견하고‘이동통신 모뎀 보안 테스팅’의 표준화* 필요성을 입증했다.
*표준화: 이동통신은 정상적인 상황에서 정상 동작을 확인하는 정합성 테스팅(Conformance Test)이 표준화되어 있으나, 비상적인 패킷을 처리한 것에 대한 표준은 아직 만들어지지 않아서 보안 테스팅의 표준화가 필요함
우리 대학 전기및전자공학부 김용대 교수팀이 경희대 박철준 교수팀과 공동연구를 통해, 스마트폰의 통신 모뎀 하위 계층에서 단 하나의 조작된 무선 패킷(네트워크의 데이터 전송 단위)만으로도 스마트폰의 통신을 마비시킬 수 있는 심각한 보안 취약점을 발견했다고 25일 밝혔다. 특히, 이 취약점들은 잠재적으로 원격 코드 실행(RCE)로 이어질 수 있다는 점에서 매우 심각하다.
연구팀은 자체 개발한 ‘LLFuzz’분석 프레임워크를 활용해, 모뎀의 하위계층 상태 전이 및 오류 처리 로직을 분석하고 보안 취약점을 탐지했다. LLFuzz는 3GPP* 표준 기반 상태 기계와 실제 단말 반응을 비교 분석함으로써 구현상의 오류로 인한 취약점을 정밀하게 추출할 수 있었다.
*3GPP: 전 세계 이동통신 표준을 만드는 국제 협력 기구
연구팀은 애플, 삼성전자, 구글, 샤오미 등 글로벌 제조사의 상용 스마트폰 15종을 대상으로 실험을 수행한 결과, 총 11개의 취약점을 발견했으며, 이 중 7개는 공식 CVE(Common Vulnerabilities and Exposures, 일반적인 취약점 및 노출) 번호를 부여받고 제조사는 이 취약점에 대한 보안패치를 적용했다. 그러나 나머지 4개는 아직 공개되지 않은 상태다.
기존 보안 연구들이 주로 NAS(Network Access Stratum, 네트워크 액세스 계층)와 RRC(Radio Resource Control, 무선 자원 제어) 등 이동통신 상위계층에 집중되었다면, 연구팀은 제조사들이 소홀히 다뤄온 이동통신 하위계층의 오류 처리 로직을 집중적으로 분석했다.
해당 취약점은 통신 모뎀의 하위계층(RLC, MAC, PDCP, PHY*)에서 발생했으며, 이들 영역은 암호화나 인증이 적용되지 않는 구조적 특성 때문에 외부 신호 주입만으로도 동작 오류가 유발될 수 있었다.
* RLC, MAC, PDCP, PHY: LTE/5G 통신의 하위 계층으로, 무선 자원 할당, 오류 제어, 암호화, 물리 계층 전송 등을 담당
연구팀은 실험용 노트북에 생성된 패킷을 소프트웨어 정의 라디오(Software-Defined Radio, SDR) 기기를 통해 상용 스마트폰에 조작된 무선 패킷(malformed MAC packet)을 주입하자, 스마트폰의 통신 모뎀(Baseband)이 즉시 크래시(crash, 동작 멈춤)되는 데모 영상을 공개했다.
※ 실험 동영상: https://drive.google.com/file/d/1NOwZdu_Hf4ScG7LkwgEkHLa_nSV4FPb_/view?usp=drive_link
영상에서는 fast.com 페이지와 초당 23MB의 데이터를 정상적으로 전송하다가, 조작된 패킷이 주입된 직후 전송이 중단되고, 마지막에는 이동통신 신호가 완전히 사라지는 장면이 포착된다. 이는 단 하나의 무선 패킷만으로 상용 기기의 통신 모뎀을 마비시킬 수 있음을 직관적으로 보여준다.
취약점은 스마트폰의 핵심 부품인 ‘모뎀 칩’에서 발견되었고 이 칩은 전화, 문자, 데이터 통신 등을 담당하는 아주 중요한 부품이다.
– Qualcomm: CVE-2025-21477, CVE-2024-23385 등 90여 종 칩셋 영향– MediaTek: CVE-2024-20076, CVE-2024-20077, CVE-2025-20659 등 80여 종– Samsung: CVE-2025-26780 (Exynos 2400, 5400 등 최신 칩셋 대상)– Apple: CVE-2024-27870 (Qualcomm CVE와 동일 취약점 공유)
문제가 된 모뎀 칩(통신용 부품)은 프리미엄 스마트폰 뿐 아니라 저가형 스마트폰, 태블릿, 스마트 워치, IoT 기기까지 포함되는 확산성으로 인해 사용자 피해 가능성이 광범위하다.
뿐만 아니라, 연구팀은 시험적으로 5G 취약점 또한 하위계층에 대해 테스트해 2주 만에 2개의 취약점을 찾았다. 5G에 대한 취약점 검사가 전반적으로 진행되지 않았던 것을 고려하면 베이스밴드 칩의 이동통신 하위계층에는 훨씬 더 많은 취약점이 존재할 수 있다.
김용대 교수는 “스마트폰 통신 모뎀의 하위계층은 암호화나 인증이 적용되지 않아, 외부에서 임의의 신호를 전송해도 단말기가 이를 수용할 수 있는 구조적 위험이 존재한다”며,“이번 연구는 스마트폰 등 IoT 기기의 이동통신 모뎀 보안 테스팅의 표준화 필요성을 입증한 사례이다”고 말했다.
연구팀은 LLFuzz를 활용해 5G 하위계층에 대한 추가적인 분석을 이어가고 있으며, LTE 및 5G 상위 계층 테스트를 위한 도구 개발 또한 진행 중이며 향후 도구 공개를 위한 협업도 추진 중이다. ‘기술의 복잡성이 높아지는 만큼, 시스템적 보안 점검 체계도 함께 진화해야 한다’는 것이 연구팀의 입장이다.
전기및전자공학부 박사과정 투안 딘 호앙(Tuan Dinh Hoang) 학생이 제1 저자로 연구 결과는 사이버보안 분야 세계 최고 권위 학회 중 하나인 유즈닉스 시큐리티(USENIX Security) 2025에서 오는 8월 발표될 예정이다.
※ 논문제목: LLFuzz: An Over-the-Air Dynamic Testing Framework for Cellular Baseband Lower Layers
(Tuan Dinh Hoang and Taekkyung Oh, KAIST; CheolJun Park, Kyung Hee Univ.; Insu Yun and Yongdae Kim, KAIST)
※ Usenix 논문 사이트: https://www.usenix.org/conference/usenixsecurity25/presentation/hoang (아직 미공개), 연구실 홈페이지 논문: https://syssec.kaist.ac.kr/pub/2025/LLFuzz_Tuan.pdf
※ 오픈 소스 저장소: https://github.com/SysSec-KAIST/LLFuzz(공개 예정)
이번 연구는 과학기술정보통신부의 재원으로 정보통신기획평가원의 지원을 받아 수행됐다.
2025.07.25 조회수 1260
단 하나의 패킷으로 스마트폰 마비시키는 보안 취약점 발견
스마트폰은 언제 어디서나 이동통신 네트워크에 연결돼 있어야 작동한다. 이러한 상시 연결성을 가능하게 하는 핵심 부품은 단말기 내부의 통신 모뎀(Baseband)이다. KAIST 연구진이 자체 개발한‘LLFuzz(Lower Layer Fuzz)’라는 테스트 프레임워크를 통해, 스마트폰 통신 모뎀 하위계층의 보안 취약점을 발견하고‘이동통신 모뎀 보안 테스팅’의 표준화* 필요성을 입증했다.
*표준화: 이동통신은 정상적인 상황에서 정상 동작을 확인하는 정합성 테스팅(Conformance Test)이 표준화되어 있으나, 비상적인 패킷을 처리한 것에 대한 표준은 아직 만들어지지 않아서 보안 테스팅의 표준화가 필요함
우리 대학 전기및전자공학부 김용대 교수팀이 경희대 박철준 교수팀과 공동연구를 통해, 스마트폰의 통신 모뎀 하위 계층에서 단 하나의 조작된 무선 패킷(네트워크의 데이터 전송 단위)만으로도 스마트폰의 통신을 마비시킬 수 있는 심각한 보안 취약점을 발견했다고 25일 밝혔다. 특히, 이 취약점들은 잠재적으로 원격 코드 실행(RCE)로 이어질 수 있다는 점에서 매우 심각하다.
연구팀은 자체 개발한 ‘LLFuzz’분석 프레임워크를 활용해, 모뎀의 하위계층 상태 전이 및 오류 처리 로직을 분석하고 보안 취약점을 탐지했다. LLFuzz는 3GPP* 표준 기반 상태 기계와 실제 단말 반응을 비교 분석함으로써 구현상의 오류로 인한 취약점을 정밀하게 추출할 수 있었다.
*3GPP: 전 세계 이동통신 표준을 만드는 국제 협력 기구
연구팀은 애플, 삼성전자, 구글, 샤오미 등 글로벌 제조사의 상용 스마트폰 15종을 대상으로 실험을 수행한 결과, 총 11개의 취약점을 발견했으며, 이 중 7개는 공식 CVE(Common Vulnerabilities and Exposures, 일반적인 취약점 및 노출) 번호를 부여받고 제조사는 이 취약점에 대한 보안패치를 적용했다. 그러나 나머지 4개는 아직 공개되지 않은 상태다.
기존 보안 연구들이 주로 NAS(Network Access Stratum, 네트워크 액세스 계층)와 RRC(Radio Resource Control, 무선 자원 제어) 등 이동통신 상위계층에 집중되었다면, 연구팀은 제조사들이 소홀히 다뤄온 이동통신 하위계층의 오류 처리 로직을 집중적으로 분석했다.
해당 취약점은 통신 모뎀의 하위계층(RLC, MAC, PDCP, PHY*)에서 발생했으며, 이들 영역은 암호화나 인증이 적용되지 않는 구조적 특성 때문에 외부 신호 주입만으로도 동작 오류가 유발될 수 있었다.
* RLC, MAC, PDCP, PHY: LTE/5G 통신의 하위 계층으로, 무선 자원 할당, 오류 제어, 암호화, 물리 계층 전송 등을 담당
연구팀은 실험용 노트북에 생성된 패킷을 소프트웨어 정의 라디오(Software-Defined Radio, SDR) 기기를 통해 상용 스마트폰에 조작된 무선 패킷(malformed MAC packet)을 주입하자, 스마트폰의 통신 모뎀(Baseband)이 즉시 크래시(crash, 동작 멈춤)되는 데모 영상을 공개했다.
※ 실험 동영상: https://drive.google.com/file/d/1NOwZdu_Hf4ScG7LkwgEkHLa_nSV4FPb_/view?usp=drive_link
영상에서는 fast.com 페이지와 초당 23MB의 데이터를 정상적으로 전송하다가, 조작된 패킷이 주입된 직후 전송이 중단되고, 마지막에는 이동통신 신호가 완전히 사라지는 장면이 포착된다. 이는 단 하나의 무선 패킷만으로 상용 기기의 통신 모뎀을 마비시킬 수 있음을 직관적으로 보여준다.
취약점은 스마트폰의 핵심 부품인 ‘모뎀 칩’에서 발견되었고 이 칩은 전화, 문자, 데이터 통신 등을 담당하는 아주 중요한 부품이다.
– Qualcomm: CVE-2025-21477, CVE-2024-23385 등 90여 종 칩셋 영향– MediaTek: CVE-2024-20076, CVE-2024-20077, CVE-2025-20659 등 80여 종– Samsung: CVE-2025-26780 (Exynos 2400, 5400 등 최신 칩셋 대상)– Apple: CVE-2024-27870 (Qualcomm CVE와 동일 취약점 공유)
문제가 된 모뎀 칩(통신용 부품)은 프리미엄 스마트폰 뿐 아니라 저가형 스마트폰, 태블릿, 스마트 워치, IoT 기기까지 포함되는 확산성으로 인해 사용자 피해 가능성이 광범위하다.
뿐만 아니라, 연구팀은 시험적으로 5G 취약점 또한 하위계층에 대해 테스트해 2주 만에 2개의 취약점을 찾았다. 5G에 대한 취약점 검사가 전반적으로 진행되지 않았던 것을 고려하면 베이스밴드 칩의 이동통신 하위계층에는 훨씬 더 많은 취약점이 존재할 수 있다.
김용대 교수는 “스마트폰 통신 모뎀의 하위계층은 암호화나 인증이 적용되지 않아, 외부에서 임의의 신호를 전송해도 단말기가 이를 수용할 수 있는 구조적 위험이 존재한다”며,“이번 연구는 스마트폰 등 IoT 기기의 이동통신 모뎀 보안 테스팅의 표준화 필요성을 입증한 사례이다”고 말했다.
연구팀은 LLFuzz를 활용해 5G 하위계층에 대한 추가적인 분석을 이어가고 있으며, LTE 및 5G 상위 계층 테스트를 위한 도구 개발 또한 진행 중이며 향후 도구 공개를 위한 협업도 추진 중이다. ‘기술의 복잡성이 높아지는 만큼, 시스템적 보안 점검 체계도 함께 진화해야 한다’는 것이 연구팀의 입장이다.
전기및전자공학부 박사과정 투안 딘 호앙(Tuan Dinh Hoang) 학생이 제1 저자로 연구 결과는 사이버보안 분야 세계 최고 권위 학회 중 하나인 유즈닉스 시큐리티(USENIX Security) 2025에서 오는 8월 발표될 예정이다.
※ 논문제목: LLFuzz: An Over-the-Air Dynamic Testing Framework for Cellular Baseband Lower Layers
(Tuan Dinh Hoang and Taekkyung Oh, KAIST; CheolJun Park, Kyung Hee Univ.; Insu Yun and Yongdae Kim, KAIST)
※ Usenix 논문 사이트: https://www.usenix.org/conference/usenixsecurity25/presentation/hoang (아직 미공개), 연구실 홈페이지 논문: https://syssec.kaist.ac.kr/pub/2025/LLFuzz_Tuan.pdf
※ 오픈 소스 저장소: https://github.com/SysSec-KAIST/LLFuzz(공개 예정)
이번 연구는 과학기술정보통신부의 재원으로 정보통신기획평가원의 지원을 받아 수행됐다.
2025.07.25 조회수 1260 -
 로봇도 사람처럼 위험할때만 즉각 반응한다
인공지능과 로봇 기술의 동반 발전 속에서, 로봇이 사람처럼 효율적으로 환경을 인식하고 반응하는 기술 확보가 중요한 과제로 떠오르고 있다. 이에 한국 연구진이 별도의 복잡한 소프트웨어나 회로 없이도 생명체의 감각 신경계를 모사한 인공 감각 신경계를 새롭게 구현해 주목받고 있다. 이 기술은 에너지 소모를 최소화하면서 외부 자극에 지능적으로 반응할 수 있어, 초소형 로봇이나 로봇 의수 등 의료 및 특수 환경에서의 활용이 기대된다.
우리 대학 전기및전자공학부 최신현 석좌교수, 충남대학교 반도체융합학과 이종원 교수 공동연구팀이 생명체의 감각 신경계 기능을 모사하는 차세대 뉴로모픽 반도체 기반 인공 감각 신경계를 개발하고, 이를 통해 외부 자극에 효율적으로 대응하는 신개념 로봇 시스템을 증명했다고 15일 밝혔다.
사람을 포함한 동물은 안전하거나 익숙한 자극은 무시하고, 중요한 자극에는 선별적으로 민감하게 반응함으로써, 에너지 낭비를 방지하면서도 중요한 자극에 집중해 민첩하게 외부 변화에 대응할 수 있다.
예를 들면, 여름철 에어컨 소리나 옷이 피부에 닿는 감촉은 곧 익숙해져 신경 쓰지 않게 되지만, 누군가 이름을 부르거나 날카로운 물체가 피부에 닿으면 재빠르게 집중하고 대응한다.
이는 감각 신경계에서의 ‘습관화’ 그리고 ‘민감화’기능에 의해서 조절됨을 보여주며, 사람처럼 효율적으로 외부 환경에 대응하는 로봇 구현을 위해, 이러한 생명체의 감각 신경계 기능을 로봇에 적용하려는 시도가 꾸준히 진행돼왔다.
그러나, 습관화나 민감화와 같은 복잡한 신경 특성을 로봇에 구현하기 위해선 별도 소프트웨어가 필요하거나, 복잡한 회로가 필요해 소형화와 에너지 효율 측면에서의 어려움이 있었다.
특히 뉴로모픽 반도체인 멤리스터(memristor)1 소자를 활용하는 시도도 있었지만, 기존 멤리스터는 단순한 전도도 변화만 가능해 신경계의 복잡한 특성을 모사하는 데 한계가 있었다.
1멤리스터: 메모리(memory)와 저항(resistor)의 합성어로 두 단자 사이로 과거에 흐른 전하량과 방향에 따라 저항값이 결정되는 차세대 전기소자
이러한 한계를 극복하기 위해 연구팀은 하나의 멤리스터 소자 안에 서로 반대 방향으로 전도도를 변화시키는 층을 형성해, 실제 감각 신경계에서처럼 습관화와 민감화 등의 기능을 모사할 수 있는 새로운 멤리스터를 개발했다.
이 소자는 자극이 반복되면 점차 반응이 줄어들다가, 위험 신호가 감지되면 다시 민감하게 반응하는 등, 실제 신경계의 복잡한 시냅스 반응 패턴을 사실적으로 재현할 수 있다.
연구팀은 이 멤리스터를 이용해 촉각과 고통을 인식하는 멤리스터 기반 인공 감각 신경계를 제작하고, 이를 실제 로봇 손에 적용해 그 효율성을 실험했다.
반복적으로 안전한 촉각 자극을 가하자, 처음에는 낯선 촉각 자극에 민감하게 반응하던 로봇 손이 점차 자극을 무시하는 습관화 특성을 보였고, 이후 전기 충격과 함께 자극을 가했을 때는 이를 위험 신호로 인식해 다시 민감하게 반응하는 민감화 특성도 확인됐다.
이를 통해, 별도의 복잡한 소프트웨어나 프로세서 없이도 로봇이 사람처럼 효율적으로 자극에 대응할 수 있음을 실험적으로 입증하며, 에너지 측면에서 효율적인 신경계 모사 로봇(neuro-inspired robot)의 개발 가능성을 검증했다.
박시온 연구원은 “사람의 감각 신경계를 차세대 반도체로 모사해, 더 똑똑하고 에너지 측면에서 효율적으로 외부 환경에 대응하는 신개념 로봇 구현의 가능성을 열었다”라며, “앞으로 초소형 로봇, 군용 로봇, 로봇 의수 같은 의료용 로봇 등 차세대 반도체와 로보틱스의 여러 융합 분야에서 활용될 것으로 기대된다”고 밝혔다.
이번 연구는 박시온 석박통합과정 연구원이 제 1저자로 국제 학술지 `네이처 커뮤니케이션즈 (Nature Communications)'에 지난 7월 1일 자로 온라인 게재됐다.
※ 논문 제목: Experimental demonstration of third-order memristor-based artificial sensory nervous system for neuro-inspired robotics
※ DOI: https://doi.org/10.1038/s41467-025-60818-x
이번 연구는 한국연구재단의 차세대지능형반도체기술개발사업, 중견연구사업, PIM인공지능반도체핵심기술개발사업, 우수신진연구사업, 그리고 나노종합기술원의 나노메디컬 디바이스 사업의 지원을 받아 수행됐다.
2025.07.15 조회수 997
로봇도 사람처럼 위험할때만 즉각 반응한다
인공지능과 로봇 기술의 동반 발전 속에서, 로봇이 사람처럼 효율적으로 환경을 인식하고 반응하는 기술 확보가 중요한 과제로 떠오르고 있다. 이에 한국 연구진이 별도의 복잡한 소프트웨어나 회로 없이도 생명체의 감각 신경계를 모사한 인공 감각 신경계를 새롭게 구현해 주목받고 있다. 이 기술은 에너지 소모를 최소화하면서 외부 자극에 지능적으로 반응할 수 있어, 초소형 로봇이나 로봇 의수 등 의료 및 특수 환경에서의 활용이 기대된다.
우리 대학 전기및전자공학부 최신현 석좌교수, 충남대학교 반도체융합학과 이종원 교수 공동연구팀이 생명체의 감각 신경계 기능을 모사하는 차세대 뉴로모픽 반도체 기반 인공 감각 신경계를 개발하고, 이를 통해 외부 자극에 효율적으로 대응하는 신개념 로봇 시스템을 증명했다고 15일 밝혔다.
사람을 포함한 동물은 안전하거나 익숙한 자극은 무시하고, 중요한 자극에는 선별적으로 민감하게 반응함으로써, 에너지 낭비를 방지하면서도 중요한 자극에 집중해 민첩하게 외부 변화에 대응할 수 있다.
예를 들면, 여름철 에어컨 소리나 옷이 피부에 닿는 감촉은 곧 익숙해져 신경 쓰지 않게 되지만, 누군가 이름을 부르거나 날카로운 물체가 피부에 닿으면 재빠르게 집중하고 대응한다.
이는 감각 신경계에서의 ‘습관화’ 그리고 ‘민감화’기능에 의해서 조절됨을 보여주며, 사람처럼 효율적으로 외부 환경에 대응하는 로봇 구현을 위해, 이러한 생명체의 감각 신경계 기능을 로봇에 적용하려는 시도가 꾸준히 진행돼왔다.
그러나, 습관화나 민감화와 같은 복잡한 신경 특성을 로봇에 구현하기 위해선 별도 소프트웨어가 필요하거나, 복잡한 회로가 필요해 소형화와 에너지 효율 측면에서의 어려움이 있었다.
특히 뉴로모픽 반도체인 멤리스터(memristor)1 소자를 활용하는 시도도 있었지만, 기존 멤리스터는 단순한 전도도 변화만 가능해 신경계의 복잡한 특성을 모사하는 데 한계가 있었다.
1멤리스터: 메모리(memory)와 저항(resistor)의 합성어로 두 단자 사이로 과거에 흐른 전하량과 방향에 따라 저항값이 결정되는 차세대 전기소자
이러한 한계를 극복하기 위해 연구팀은 하나의 멤리스터 소자 안에 서로 반대 방향으로 전도도를 변화시키는 층을 형성해, 실제 감각 신경계에서처럼 습관화와 민감화 등의 기능을 모사할 수 있는 새로운 멤리스터를 개발했다.
이 소자는 자극이 반복되면 점차 반응이 줄어들다가, 위험 신호가 감지되면 다시 민감하게 반응하는 등, 실제 신경계의 복잡한 시냅스 반응 패턴을 사실적으로 재현할 수 있다.
연구팀은 이 멤리스터를 이용해 촉각과 고통을 인식하는 멤리스터 기반 인공 감각 신경계를 제작하고, 이를 실제 로봇 손에 적용해 그 효율성을 실험했다.
반복적으로 안전한 촉각 자극을 가하자, 처음에는 낯선 촉각 자극에 민감하게 반응하던 로봇 손이 점차 자극을 무시하는 습관화 특성을 보였고, 이후 전기 충격과 함께 자극을 가했을 때는 이를 위험 신호로 인식해 다시 민감하게 반응하는 민감화 특성도 확인됐다.
이를 통해, 별도의 복잡한 소프트웨어나 프로세서 없이도 로봇이 사람처럼 효율적으로 자극에 대응할 수 있음을 실험적으로 입증하며, 에너지 측면에서 효율적인 신경계 모사 로봇(neuro-inspired robot)의 개발 가능성을 검증했다.
박시온 연구원은 “사람의 감각 신경계를 차세대 반도체로 모사해, 더 똑똑하고 에너지 측면에서 효율적으로 외부 환경에 대응하는 신개념 로봇 구현의 가능성을 열었다”라며, “앞으로 초소형 로봇, 군용 로봇, 로봇 의수 같은 의료용 로봇 등 차세대 반도체와 로보틱스의 여러 융합 분야에서 활용될 것으로 기대된다”고 밝혔다.
이번 연구는 박시온 석박통합과정 연구원이 제 1저자로 국제 학술지 `네이처 커뮤니케이션즈 (Nature Communications)'에 지난 7월 1일 자로 온라인 게재됐다.
※ 논문 제목: Experimental demonstration of third-order memristor-based artificial sensory nervous system for neuro-inspired robotics
※ DOI: https://doi.org/10.1038/s41467-025-60818-x
이번 연구는 한국연구재단의 차세대지능형반도체기술개발사업, 중견연구사업, PIM인공지능반도체핵심기술개발사업, 우수신진연구사업, 그리고 나노종합기술원의 나노메디컬 디바이스 사업의 지원을 받아 수행됐다.
2025.07.15 조회수 997 -
 최정우 교수팀, 세계 최고 음향 AI 챌린지 세계 1위 쾌거
‘음향 분리 및 분류 기술’은 드론, 공장 배관, 국경 감시 시스템 등에서 이상 음향을 조기에 탐지하거나, AR/VR 콘텐츠 제작 시 공간 음향(Spatial Audio)을 음원별로 분리해 편집할 수 있도록 하는 차세대 인공지능(AI) 핵심 기술이다.
우리 대학 전기및전자공학부 최정우 교수 연구팀이 세계 최고 권위의 음향 탐지 및 분석 대회인 ‘IEEE DCASE 챌린지 2025’에서 ‘공간 의미 기반 음향 장면 분할(Spatial Semantic Segmentation of Sound Scenes)’ 분야에서 우승을 차지했다고 11일 밝혔다.
이번 대회에서 연구팀은 전 세계 86개 참가팀과 총 6개 분야에서 경쟁 끝에 최초 참가임에도 세계 1위 성과를 거두었다. KAIST 최정우 교수 연구팀은 이동헌 박사, 권영후 석박통합과정생, 김도환 석사과정생으로 구성되었다.
연구팀이 참가한 ‘공간 의미 기반 음향 장면 분할’의 ‘태스크(Task) 4’분야는 여러 음원이 혼합된 다채널 신호의 공간 정보를 분석해 개별 소리를 분리하고 18종으로의 분류를 수행해야 하는 기술 난이도가 매우 높은 분야이다. 연구팀은 오는 10월, 바르셀로나에서 열리는 DCASE 워크숍에서 기술을 발표할 예정이다.
연구팀의 이동헌 박사는 올해 초 트랜스포머(Transformer)와 맘바(Mamba) 아키텍처를 결합한 세계 최고 성능의 음원 분리 인공지능을 개발했으며, 챌린지 기간 동안 권영후 연구원을 중심으로 1차로 분리된 음원의 파형과 종류를 단서로 해 다시 음원 분리와 분류를 수행하는‘단계적 추론 방식’의 AI 모델을 완성했다.
이는 사람이 복잡한 소리를 들을 때 소리의 종류나 리듬, 방향 등 특정 단서에 기반해 개별 소리를 분리해 듣는 방식을 AI가 모방한 모델이다.
이를 통해, 순위를 결정하는 척도인 AI가 소리를 얼마나 잘 분리하고 분류했는지 평가하는‘음원의 신호대 왜곡비 향상도(CA-SDRi)*’에서 참가팀 중 유일하게 두 자릿수 대의 성능(11 dB)을 보여, 기술적인 우수성을 입증하였다.
*음원의 신호대 왜곡비 향상도(CA-SDRi): 기존의 오디오와 비교해 얼마나 더 선명하게(덜 왜곡되게) 원하는 소리를 분리했는지를 dB(데시벨) 단위로 측정하고 숫자가 클수록 더 정확하고 깔끔하게 소리를 분리했다는 뜻임
최정우 교수는 "연구팀은 최근 3년간 세계 최고의 음향 분리 AI 모델을 선보여 왔으며, 그 결과를 공식적으로 인정받는 계기가 되어 기쁘다”면서 “난이도가 대폭 향상되고, 타 학회 일정과 기말고사로 불과 몇 주간만 개발이 가능했음에도 집중력 있는 연구를 통해 1위를 차지한 연구팀 개개인이 자랑스럽다”고 소감을 밝혔다.
‘IEEE DCASE 챌린지 2025’는 온라인으로 진행됐으며, 4월 1일부터 시작해 6월 15일 인공지능 모델 투고를 마감했고 지난 6월 30일 결과가 발표됐다. 각종 음향 관련 탐지 및 분류 기술을 평가하는 IEEE 신호처리학회(Signal Processing Society) 산하 국제대회인 본 챌린지는 2013년 개최된 이래 음향 분야 인공지능 모델의 세계적인 경연의 장으로 자리매김해 왔다.
https://dcase.community/challenge2025/task-spatial-semantic-segmentation-of-sound-scenes
한편, 해당 연구는 교육과학기술부의 재원으로 한국연구재단 중견연구자지원사업, STEAM 연구사업 지원 및 방위사업청 및 국방과학연구소 재원으로 미래국방연구센터 지원을 받아 수행됐다.
2025.07.11 조회수 1224
최정우 교수팀, 세계 최고 음향 AI 챌린지 세계 1위 쾌거
‘음향 분리 및 분류 기술’은 드론, 공장 배관, 국경 감시 시스템 등에서 이상 음향을 조기에 탐지하거나, AR/VR 콘텐츠 제작 시 공간 음향(Spatial Audio)을 음원별로 분리해 편집할 수 있도록 하는 차세대 인공지능(AI) 핵심 기술이다.
우리 대학 전기및전자공학부 최정우 교수 연구팀이 세계 최고 권위의 음향 탐지 및 분석 대회인 ‘IEEE DCASE 챌린지 2025’에서 ‘공간 의미 기반 음향 장면 분할(Spatial Semantic Segmentation of Sound Scenes)’ 분야에서 우승을 차지했다고 11일 밝혔다.
이번 대회에서 연구팀은 전 세계 86개 참가팀과 총 6개 분야에서 경쟁 끝에 최초 참가임에도 세계 1위 성과를 거두었다. KAIST 최정우 교수 연구팀은 이동헌 박사, 권영후 석박통합과정생, 김도환 석사과정생으로 구성되었다.
연구팀이 참가한 ‘공간 의미 기반 음향 장면 분할’의 ‘태스크(Task) 4’분야는 여러 음원이 혼합된 다채널 신호의 공간 정보를 분석해 개별 소리를 분리하고 18종으로의 분류를 수행해야 하는 기술 난이도가 매우 높은 분야이다. 연구팀은 오는 10월, 바르셀로나에서 열리는 DCASE 워크숍에서 기술을 발표할 예정이다.
연구팀의 이동헌 박사는 올해 초 트랜스포머(Transformer)와 맘바(Mamba) 아키텍처를 결합한 세계 최고 성능의 음원 분리 인공지능을 개발했으며, 챌린지 기간 동안 권영후 연구원을 중심으로 1차로 분리된 음원의 파형과 종류를 단서로 해 다시 음원 분리와 분류를 수행하는‘단계적 추론 방식’의 AI 모델을 완성했다.
이는 사람이 복잡한 소리를 들을 때 소리의 종류나 리듬, 방향 등 특정 단서에 기반해 개별 소리를 분리해 듣는 방식을 AI가 모방한 모델이다.
이를 통해, 순위를 결정하는 척도인 AI가 소리를 얼마나 잘 분리하고 분류했는지 평가하는‘음원의 신호대 왜곡비 향상도(CA-SDRi)*’에서 참가팀 중 유일하게 두 자릿수 대의 성능(11 dB)을 보여, 기술적인 우수성을 입증하였다.
*음원의 신호대 왜곡비 향상도(CA-SDRi): 기존의 오디오와 비교해 얼마나 더 선명하게(덜 왜곡되게) 원하는 소리를 분리했는지를 dB(데시벨) 단위로 측정하고 숫자가 클수록 더 정확하고 깔끔하게 소리를 분리했다는 뜻임
최정우 교수는 "연구팀은 최근 3년간 세계 최고의 음향 분리 AI 모델을 선보여 왔으며, 그 결과를 공식적으로 인정받는 계기가 되어 기쁘다”면서 “난이도가 대폭 향상되고, 타 학회 일정과 기말고사로 불과 몇 주간만 개발이 가능했음에도 집중력 있는 연구를 통해 1위를 차지한 연구팀 개개인이 자랑스럽다”고 소감을 밝혔다.
‘IEEE DCASE 챌린지 2025’는 온라인으로 진행됐으며, 4월 1일부터 시작해 6월 15일 인공지능 모델 투고를 마감했고 지난 6월 30일 결과가 발표됐다. 각종 음향 관련 탐지 및 분류 기술을 평가하는 IEEE 신호처리학회(Signal Processing Society) 산하 국제대회인 본 챌린지는 2013년 개최된 이래 음향 분야 인공지능 모델의 세계적인 경연의 장으로 자리매김해 왔다.
https://dcase.community/challenge2025/task-spatial-semantic-segmentation-of-sound-scenes
한편, 해당 연구는 교육과학기술부의 재원으로 한국연구재단 중견연구자지원사업, STEAM 연구사업 지원 및 방위사업청 및 국방과학연구소 재원으로 미래국방연구센터 지원을 받아 수행됐다.
2025.07.11 조회수 1224 -
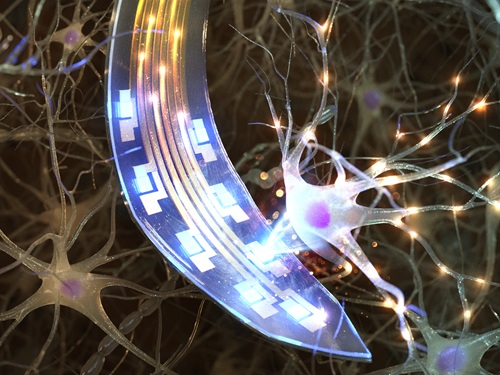 마이크로 OLED로 난치성 뇌질환 치료 '게임 체인저' 기술 제시
광유전학 기술은 빛에 반응하는 광 단백질이 발현된 뉴런에 특정 파장의 빛 자극을 통해 뉴런의 활성을 조절하는 기술로 다양한 뇌질환의 원인을 규명하며 난치성 뇌질환의 새로운 치료 방법을 개발할 가능성을 열고 있다. 이 기술은 인체의 뇌에 삽입하여 자극을 주는 의료 기기인 ‘뉴럴 프로브’를 통해 정확하게 자극하고 무른 뇌 조직의 손상을 최소화해야 한다. 이에 우리 연구진이 마이크로 OLED를 활용해 얇고 유연한 인체 삽입형 의료기기로 구현함으로써 뉴럴 프로브의 새로운 패러다임을 제시했다.
우리 대학 전기및전자공학부 최경철 교수와 이현주 연구팀이 공동 연구를 통해, 유연한 마이크로 OLED가 집적된 광유전학용 뉴럴 프로브 개발에 성공했다고 6일 밝혔다.
광유전학 연구에서 주요 기술은 광원의 빛을 뇌로 전달하는 방식으로 외부 광원으로부터의 깊은 뇌 영역까지 빛을 전달하기 위해 수십 년간 광섬유를 사용해 왔다. 하지만 단일 뉴런을 자극하기 위한 유연 광섬유, 초미세 광원 집적 뉴럴 프로브 등 관련 연구가 이뤄지고 있다.
연구팀은 마이크로 OLED는 높은 공간적 해상도와 유연성을 가져, 매우 작은 영역의 뉴런에서도 정확하게 빛을 조사할 수 있어 세밀한 뇌 회로 분석이 가능하고 동물의 움직임에 불편함을 주지 않으면서 부작용을 최소화하는 장점에 주목했다. 그뿐만 아니라, 미세한 파장 조절을 통해 정밀한 빛 조절이 가능하며 다중 자극을 통한 복잡한 뇌 기능 연구가 가능하다.
하지만, 체내 수분이나 물에 의해 전기적 특성이 쉽게 열화되기 때문에 생체 삽입형 전자장치로 활용되는데 한계가 있었고, 얇고 유연한 탐침 위 고해상도 집적 공정에 대한 세부적인 최적화도 필요했다.
공동연구팀은 수분과 산소가 많은 생체 내 환경에서 OLED의 구동 신뢰성을 높이며 생체 삽입 시 조직 손상을 최소화하고자, 산화알루미늄/파릴렌-C(Al2O3/parylene-C)로 구성된 초박막 유연 봉지막*을 얇은 탐침 형태인 260~600마이크로미터(μm) 너비로 패터닝해 생체친화성을 유지했다.
* 봉지막: 소자를 외부 환경요인인 산소와 물 분자로부터 완전히 차단하는 막 기술로 소자의 수명을 유지시키고 신뢰성을 줌
또한, 고해상도 마이크로 OLED를 집적함에 있어 전체 소자의 유연성과 생체친화성을 유지하기 위해, 봉지막과 동일한 생체친화 재료인 파릴렌-C(parylene-C)를 활용하였다. 아울러, 인접한 OLED 픽셀 간 전기적 간섭 현상을 제거하고 각 픽셀을 공간적으로 분리하기 위해 구조적 레이어인 ‘화소 정의막(pixel define layer)’을 도입함으로써, 8개의 마이크로 OLED를 독립적으로 개별 구동할 수 있도록 구현했다.
마지막으로, 소자 내 다중 박막층의 잔류 응력과 두께를 정밀하게 조절함으로써, 생체 내 환경에서도 소자의 유연성을 유지할 수 있도록 하였다. 이를 통해 외부 셔틀이나 바늘과 같은 보조 장치 없이도 단일 탐침만으로 휘어짐 없이 삽입이 가능하도록, 소자의 기계적 스트레스를 최적화해 설계했다.
결론적으로 연구팀은 채널로돕신2의 활성화에 적합한 470나노미터(nm) 파장에서 1밀리와트/제곱밀리미터(mW/mm2)이상의 광 파워 밀도를 가지는 즉, 광유전학 및 생체조직 자극 응용에서 상당히 높은 수준의 광출력을 가진 마이크로 OLED 집적 유연 뉴럴 프로브를 개발했다.
또한, 초박막 유연 봉지막은 2.66×10⁻⁵ g/m²/day의 낮은 수분 투습률을 보이며 소자 수명은 10년 이상 유지할 수 있고, 패릴렌-C(parylene-C)를 기반으로 생체 내 높은 봉지막 성능을 발휘하며, 전기적 간섭과 휨 이슈 없이 집적된 OLED의 개별 구동을 성공적으로 시연했다.
이번 연구를 주도한 최경철 교수 연구팀의 이소민 박사는 “고유연·고해상도의 마이크로 OLED를 얇은 유연 탐침 위에 집적하는 세부 공정 및 생체 적용성, 친화성 향상에 집중했다”며 “이번 연구는 기존 연구를 넘어 유연 프로브 형태에 최초로 개발해 보고된 사례로, 유연 OLED가 인체 삽입형 측정 및 치료 의료기기로서의 새로운 패러다임을 제시할 것으로 기대된다”고 말했다.
이번 연구는 전기및전자공학부 이소민 박사가 제1 저자로 나노 분야의 권위 있는 국제 학술지 `어드밴스드 펑셔널 머터리얼즈(Advanced Functional Materials, IF 18.5)'에 지난 3월 26일 字로 온라인 게재됐으며, 전면 표지 논문으로 이번 7월에 선정됐다.
※ 논문명: Advanced Micro-OLED Integration on Thin and Flexible Polymer Neural Probes for Targeted Optogenetic Stimulation
※ DOI: https://doi.org/10.1002/adfm.202420758
한편, 이번 연구는 과학기술정보통신부 한국연구재단의 전자약 기술개발사업(연구 과제명: 뇌인지-정서 향상 빛 자극 전자약의 핵심원천기술 개발 및 생체 적용가능성 검증)의 지원을 받아 수행됐다.
2025.07.07 조회수 1297
마이크로 OLED로 난치성 뇌질환 치료 '게임 체인저' 기술 제시
광유전학 기술은 빛에 반응하는 광 단백질이 발현된 뉴런에 특정 파장의 빛 자극을 통해 뉴런의 활성을 조절하는 기술로 다양한 뇌질환의 원인을 규명하며 난치성 뇌질환의 새로운 치료 방법을 개발할 가능성을 열고 있다. 이 기술은 인체의 뇌에 삽입하여 자극을 주는 의료 기기인 ‘뉴럴 프로브’를 통해 정확하게 자극하고 무른 뇌 조직의 손상을 최소화해야 한다. 이에 우리 연구진이 마이크로 OLED를 활용해 얇고 유연한 인체 삽입형 의료기기로 구현함으로써 뉴럴 프로브의 새로운 패러다임을 제시했다.
우리 대학 전기및전자공학부 최경철 교수와 이현주 연구팀이 공동 연구를 통해, 유연한 마이크로 OLED가 집적된 광유전학용 뉴럴 프로브 개발에 성공했다고 6일 밝혔다.
광유전학 연구에서 주요 기술은 광원의 빛을 뇌로 전달하는 방식으로 외부 광원으로부터의 깊은 뇌 영역까지 빛을 전달하기 위해 수십 년간 광섬유를 사용해 왔다. 하지만 단일 뉴런을 자극하기 위한 유연 광섬유, 초미세 광원 집적 뉴럴 프로브 등 관련 연구가 이뤄지고 있다.
연구팀은 마이크로 OLED는 높은 공간적 해상도와 유연성을 가져, 매우 작은 영역의 뉴런에서도 정확하게 빛을 조사할 수 있어 세밀한 뇌 회로 분석이 가능하고 동물의 움직임에 불편함을 주지 않으면서 부작용을 최소화하는 장점에 주목했다. 그뿐만 아니라, 미세한 파장 조절을 통해 정밀한 빛 조절이 가능하며 다중 자극을 통한 복잡한 뇌 기능 연구가 가능하다.
하지만, 체내 수분이나 물에 의해 전기적 특성이 쉽게 열화되기 때문에 생체 삽입형 전자장치로 활용되는데 한계가 있었고, 얇고 유연한 탐침 위 고해상도 집적 공정에 대한 세부적인 최적화도 필요했다.
공동연구팀은 수분과 산소가 많은 생체 내 환경에서 OLED의 구동 신뢰성을 높이며 생체 삽입 시 조직 손상을 최소화하고자, 산화알루미늄/파릴렌-C(Al2O3/parylene-C)로 구성된 초박막 유연 봉지막*을 얇은 탐침 형태인 260~600마이크로미터(μm) 너비로 패터닝해 생체친화성을 유지했다.
* 봉지막: 소자를 외부 환경요인인 산소와 물 분자로부터 완전히 차단하는 막 기술로 소자의 수명을 유지시키고 신뢰성을 줌
또한, 고해상도 마이크로 OLED를 집적함에 있어 전체 소자의 유연성과 생체친화성을 유지하기 위해, 봉지막과 동일한 생체친화 재료인 파릴렌-C(parylene-C)를 활용하였다. 아울러, 인접한 OLED 픽셀 간 전기적 간섭 현상을 제거하고 각 픽셀을 공간적으로 분리하기 위해 구조적 레이어인 ‘화소 정의막(pixel define layer)’을 도입함으로써, 8개의 마이크로 OLED를 독립적으로 개별 구동할 수 있도록 구현했다.
마지막으로, 소자 내 다중 박막층의 잔류 응력과 두께를 정밀하게 조절함으로써, 생체 내 환경에서도 소자의 유연성을 유지할 수 있도록 하였다. 이를 통해 외부 셔틀이나 바늘과 같은 보조 장치 없이도 단일 탐침만으로 휘어짐 없이 삽입이 가능하도록, 소자의 기계적 스트레스를 최적화해 설계했다.
결론적으로 연구팀은 채널로돕신2의 활성화에 적합한 470나노미터(nm) 파장에서 1밀리와트/제곱밀리미터(mW/mm2)이상의 광 파워 밀도를 가지는 즉, 광유전학 및 생체조직 자극 응용에서 상당히 높은 수준의 광출력을 가진 마이크로 OLED 집적 유연 뉴럴 프로브를 개발했다.
또한, 초박막 유연 봉지막은 2.66×10⁻⁵ g/m²/day의 낮은 수분 투습률을 보이며 소자 수명은 10년 이상 유지할 수 있고, 패릴렌-C(parylene-C)를 기반으로 생체 내 높은 봉지막 성능을 발휘하며, 전기적 간섭과 휨 이슈 없이 집적된 OLED의 개별 구동을 성공적으로 시연했다.
이번 연구를 주도한 최경철 교수 연구팀의 이소민 박사는 “고유연·고해상도의 마이크로 OLED를 얇은 유연 탐침 위에 집적하는 세부 공정 및 생체 적용성, 친화성 향상에 집중했다”며 “이번 연구는 기존 연구를 넘어 유연 프로브 형태에 최초로 개발해 보고된 사례로, 유연 OLED가 인체 삽입형 측정 및 치료 의료기기로서의 새로운 패러다임을 제시할 것으로 기대된다”고 말했다.
이번 연구는 전기및전자공학부 이소민 박사가 제1 저자로 나노 분야의 권위 있는 국제 학술지 `어드밴스드 펑셔널 머터리얼즈(Advanced Functional Materials, IF 18.5)'에 지난 3월 26일 字로 온라인 게재됐으며, 전면 표지 논문으로 이번 7월에 선정됐다.
※ 논문명: Advanced Micro-OLED Integration on Thin and Flexible Polymer Neural Probes for Targeted Optogenetic Stimulation
※ DOI: https://doi.org/10.1002/adfm.202420758
한편, 이번 연구는 과학기술정보통신부 한국연구재단의 전자약 기술개발사업(연구 과제명: 뇌인지-정서 향상 빛 자극 전자약의 핵심원천기술 개발 및 생체 적용가능성 검증)의 지원을 받아 수행됐다.
2025.07.07 조회수 1297 -
 24시간 말하는 AI비서 가능성 여는 '스피치SSM' 개발
최근 음성 언어 모델(Spoken Language Model, SLM)은 텍스트 없이 인간의 음성을 학습해 음성의 언어적, 비언어적 정보를 이해 및 생성하는 기술로 텍스트 기반 언어 모델의 한계를 넘어서는 차세대 기술로 각광받고 있다. 하지만 기존 모델은 장시간 콘텐츠 생성이 요구되는 팟캐스트, 오디오북, 음성비서 등에서 한계가 두드러졌는데, 우리 연구진이 이런 한계를 뛰어넘어, 시간 제약 없이 일관되고 자연스러운 음성 생성을 실현한 ‘스피치SSM’을 개발하는데 성공했다.
우리 대학 전기및전자공학부 노용만 교수 연구팀의 박세진 연구원(박사과정)이 장시간 음성 생성이 가능한 음성 언어 모델 ‘스피치SSM(SpeechSSM)’을 개발했다고 3일 밝혔다.
이번 연구는 국제 최고 권위 머신러닝 학회인 ICML(International Conference on Machine Learning) 2025에 전체 제출된 논문 중 약 1%만이 선정되는 구두 논문 발표에 확정돼 뛰어난 연구 역량을 입증할 뿐만 아니라 우리 대학의 인공지능 연구 능력이 세계 최고 수준임을 다시 한번 보여주는 계기가 될 전망이다.
음성 언어 모델(SLM)은 중간에 텍스트로 변환하지 않고 음성을 직접 처리함으로써, 인간 화자 고유의 음향적 특성을 활용할 수 있어 대규모 모델에서도 고품질의 음성을 빠르게 생성할 수 있다는 점이 큰 강점이다.
그러나 기존 모델은 음성을 아주 세밀하게 잘게 쪼개서 아주 자세한 정보까지 담는 경우, ‘음성 토큰 해상도’가 높아지고 사용하는 메모리 소비도 증가하는 문제로 인해 장시간 음성의 의미적, 화자적 일관성을 유지하기 어려웠다.
연구팀은 이러한 문제를 해결하기 위해 하이브리드 상태공간 모델(Hybrid State-Space Model)을 사용한 음성 언어 모델인‘스피치SSM’를 개발해 긴 음성 시퀀스를 효율적으로 처리하고 생성할 수 있게 설계했다.
이 모델은 최근 정보에 집중하는 ‘어텐션 레이어(attention layer)’와 전체 이야기 흐름(장기적인 맥락)을 오래 기억하는 ‘순환 레이어(recurrent layer)’를 교차 배치한 ‘하이브리드 구조’를 통해 긴 시간 동안 음성을 생성해도 흐름을 잃지 않고 이야기를 잘 이어간다. 또한, 메모리 사용량과 연산량이 입력 길이에 따라 급격히 증가하지 않아, 장시간의 음성을 안정적이고 효율적으로 학습하고 생성할 수 있다.
스피치SSM은 음성 데이터를 짧은 고정된 단위(윈도우)로 나눠 각 단위별로 독립적으로 처리하고, 전체 긴 음성을 만들 경우에는 다시 붙이는 방식을 활용해 쉽게 긴 음성을 만들 수 있어 무한한 길이의 음성 시퀀스(unbounded speech sequence)를 효과적으로 처리할 수 있게 했다.
또한 음성 생성 단계에서는 한 글자, 한 단어 차례대로 천천히 만들어내지 않고, 여러 부분을 한꺼번에 빠르게 만들어내는 ‘비자기회귀(Non-Autoregressive)’방식의 오디오 합성 모델(SoundStorm)을 사용해, 고품질의 음성을 빠르게 생성할 수 있게 했다.
기존은 10초 정도 짧은 음성 모델을 평가했지만, 연구팀은 16분까지 생성할 수 있도록 자체 구축한 새로운 벤치마크 데이터셋인 ‘LibriSpeech-Long'을 기반으로 음성을 생성하는 평가 태스크를 새롭게 만들었다.
기존 음성 모델 평가 지표인 말이 문법적으로 맞는지 정도만 알려주는 PPL(Perplexity)에 비해, 연구팀은 시간이 지나면서도 내용이 잘 이어지는지 보는 'SC-L(semantic coherence over time)', 자연스럽게 들리는 정도를 시간 따라 보는 'N-MOS-T(naturalness mean opinion score over time)' 등 새로운 평가 지표들을 제안해 보다 효과적이고 정밀하게 평가했다.
새로운 평가를 통해 스피치SSM 음성 언어 모델로 생성된 음성은 긴 시간 생성에도 불구하고 초기 프롬프트에서 언급된 특정 인물이 지속적으로 등장하며, 맥락적으로 일관된 새로운 인물과 사건들이 자연스럽게 전개되는 모습을 확인했다. 이는 기존 모델들이 장시간 생성 시 쉽게 주제를 잃고 반복되는 현상을 보였던 것과 크게 대조적이다.
박세진 박사과정생은 “기존 음성 언어 모델은 장시간 생성에 한계가 있어, 실제 인간이 사용하도록 장시간 음성 생성이 가능한 음성 언어 모델을 개발하는 것이 목표였다”며 “이번 연구 성과를 통해 긴 문맥에서도 일관된 내용을 유지하면서, 기존 방식보다 더 효율적이고 빠르게 실시간으로 응답할 수 있어, 다양한 음성 콘텐츠 제작과 음성비서 등 음성 AI 분야에 크게 기여할 것으로 기대한다”라고 밝혔다.
이 연구는 제1 저자인 우리 대학 박세진 박사과정 학생이 구글 딥마인드(Google DeepMind)와 협력해, ICML(국제 머신러닝 학회) 2025에서 7월 16일 구두 발표로 소개될 예정이다.
※ 논문제목: Long-Form Speech Generation with Spoken Language Models
※ DOI: 10.48550/arXiv.2412.18603
한편, 박세진 박사과정생은 비전, 음성, 언어를 통합하는 연구를 수행하며 CVPR(컴퓨터 비전 분야 최고 학회) 2024 하이라이트 논문 발표, 2024년 ACL(자연어 처리 분야 최고 학회)에서 우수논문상(Outstanding Paper Award) 수상 등을 통해 우수한 연구 역량을 입증한 바 있다.
[데모 페이지 링크]
https://google.github.io/tacotron/publications/speechssm/
2025.07.03 조회수 1562
24시간 말하는 AI비서 가능성 여는 '스피치SSM' 개발
최근 음성 언어 모델(Spoken Language Model, SLM)은 텍스트 없이 인간의 음성을 학습해 음성의 언어적, 비언어적 정보를 이해 및 생성하는 기술로 텍스트 기반 언어 모델의 한계를 넘어서는 차세대 기술로 각광받고 있다. 하지만 기존 모델은 장시간 콘텐츠 생성이 요구되는 팟캐스트, 오디오북, 음성비서 등에서 한계가 두드러졌는데, 우리 연구진이 이런 한계를 뛰어넘어, 시간 제약 없이 일관되고 자연스러운 음성 생성을 실현한 ‘스피치SSM’을 개발하는데 성공했다.
우리 대학 전기및전자공학부 노용만 교수 연구팀의 박세진 연구원(박사과정)이 장시간 음성 생성이 가능한 음성 언어 모델 ‘스피치SSM(SpeechSSM)’을 개발했다고 3일 밝혔다.
이번 연구는 국제 최고 권위 머신러닝 학회인 ICML(International Conference on Machine Learning) 2025에 전체 제출된 논문 중 약 1%만이 선정되는 구두 논문 발표에 확정돼 뛰어난 연구 역량을 입증할 뿐만 아니라 우리 대학의 인공지능 연구 능력이 세계 최고 수준임을 다시 한번 보여주는 계기가 될 전망이다.
음성 언어 모델(SLM)은 중간에 텍스트로 변환하지 않고 음성을 직접 처리함으로써, 인간 화자 고유의 음향적 특성을 활용할 수 있어 대규모 모델에서도 고품질의 음성을 빠르게 생성할 수 있다는 점이 큰 강점이다.
그러나 기존 모델은 음성을 아주 세밀하게 잘게 쪼개서 아주 자세한 정보까지 담는 경우, ‘음성 토큰 해상도’가 높아지고 사용하는 메모리 소비도 증가하는 문제로 인해 장시간 음성의 의미적, 화자적 일관성을 유지하기 어려웠다.
연구팀은 이러한 문제를 해결하기 위해 하이브리드 상태공간 모델(Hybrid State-Space Model)을 사용한 음성 언어 모델인‘스피치SSM’를 개발해 긴 음성 시퀀스를 효율적으로 처리하고 생성할 수 있게 설계했다.
이 모델은 최근 정보에 집중하는 ‘어텐션 레이어(attention layer)’와 전체 이야기 흐름(장기적인 맥락)을 오래 기억하는 ‘순환 레이어(recurrent layer)’를 교차 배치한 ‘하이브리드 구조’를 통해 긴 시간 동안 음성을 생성해도 흐름을 잃지 않고 이야기를 잘 이어간다. 또한, 메모리 사용량과 연산량이 입력 길이에 따라 급격히 증가하지 않아, 장시간의 음성을 안정적이고 효율적으로 학습하고 생성할 수 있다.
스피치SSM은 음성 데이터를 짧은 고정된 단위(윈도우)로 나눠 각 단위별로 독립적으로 처리하고, 전체 긴 음성을 만들 경우에는 다시 붙이는 방식을 활용해 쉽게 긴 음성을 만들 수 있어 무한한 길이의 음성 시퀀스(unbounded speech sequence)를 효과적으로 처리할 수 있게 했다.
또한 음성 생성 단계에서는 한 글자, 한 단어 차례대로 천천히 만들어내지 않고, 여러 부분을 한꺼번에 빠르게 만들어내는 ‘비자기회귀(Non-Autoregressive)’방식의 오디오 합성 모델(SoundStorm)을 사용해, 고품질의 음성을 빠르게 생성할 수 있게 했다.
기존은 10초 정도 짧은 음성 모델을 평가했지만, 연구팀은 16분까지 생성할 수 있도록 자체 구축한 새로운 벤치마크 데이터셋인 ‘LibriSpeech-Long'을 기반으로 음성을 생성하는 평가 태스크를 새롭게 만들었다.
기존 음성 모델 평가 지표인 말이 문법적으로 맞는지 정도만 알려주는 PPL(Perplexity)에 비해, 연구팀은 시간이 지나면서도 내용이 잘 이어지는지 보는 'SC-L(semantic coherence over time)', 자연스럽게 들리는 정도를 시간 따라 보는 'N-MOS-T(naturalness mean opinion score over time)' 등 새로운 평가 지표들을 제안해 보다 효과적이고 정밀하게 평가했다.
새로운 평가를 통해 스피치SSM 음성 언어 모델로 생성된 음성은 긴 시간 생성에도 불구하고 초기 프롬프트에서 언급된 특정 인물이 지속적으로 등장하며, 맥락적으로 일관된 새로운 인물과 사건들이 자연스럽게 전개되는 모습을 확인했다. 이는 기존 모델들이 장시간 생성 시 쉽게 주제를 잃고 반복되는 현상을 보였던 것과 크게 대조적이다.
박세진 박사과정생은 “기존 음성 언어 모델은 장시간 생성에 한계가 있어, 실제 인간이 사용하도록 장시간 음성 생성이 가능한 음성 언어 모델을 개발하는 것이 목표였다”며 “이번 연구 성과를 통해 긴 문맥에서도 일관된 내용을 유지하면서, 기존 방식보다 더 효율적이고 빠르게 실시간으로 응답할 수 있어, 다양한 음성 콘텐츠 제작과 음성비서 등 음성 AI 분야에 크게 기여할 것으로 기대한다”라고 밝혔다.
이 연구는 제1 저자인 우리 대학 박세진 박사과정 학생이 구글 딥마인드(Google DeepMind)와 협력해, ICML(국제 머신러닝 학회) 2025에서 7월 16일 구두 발표로 소개될 예정이다.
※ 논문제목: Long-Form Speech Generation with Spoken Language Models
※ DOI: 10.48550/arXiv.2412.18603
한편, 박세진 박사과정생은 비전, 음성, 언어를 통합하는 연구를 수행하며 CVPR(컴퓨터 비전 분야 최고 학회) 2024 하이라이트 논문 발표, 2024년 ACL(자연어 처리 분야 최고 학회)에서 우수논문상(Outstanding Paper Award) 수상 등을 통해 우수한 연구 역량을 입증한 바 있다.
[데모 페이지 링크]
https://google.github.io/tacotron/publications/speechssm/
2025.07.03 조회수 1562 -
 배터리 없이 이산화탄소 실시간 모니터링 성공
기후 변화와 지구온난화를 막기 위해서는 이산화탄소(CO2)가 ‘얼마나’ 배출되고 있는지를 정확히 파악하는 것이 핵심이다. 이를 가능하게 하는 것이 바로 이산화탄소 모니터링 기술이다. 최근 한국 연구진이 외부 전력 없이도 이산화탄소 농도를 실시간 측정하고 무선으로 전송할 수 있는 시스템을 개발해 환경 모니터링 기술의 새로운 가능성을 열었다.
우리 대학 전기및전자공학부 권경하 교수 연구팀이 중앙대학교 류한준 교수팀과 공동연구를 통해, 주변의 미세 진동 에너지를 수확해 이산화탄소 농도를 주기적으로 측정할 수 있는 자가발전형 무선 모니터링 시스템을 개발했다고 9일 밝혔다.
지구온난화의 주요 원인인 이산화탄소 배출은 산업계의 지속가능성 평가 지표로 자리 잡고 있으며, 유럽연합(EU)은 이미 공장 배출량 규제를 도입한 상태다. 이러한 규제 흐름에 따라, 효율적이고 지속 가능한 이산화탄소 모니터링 시스템은 환경 관리와 산업 공정 제어에 필수적인 요소로 주목받고 있다.
그러나 기존 이산화탄소 모니터링 시스템은 대부분 배터리나 유선 전원에 의존하기 때문에 설치와 유지보수에 제약이 따른다. 연구팀은 이 문제를 해결하기 위해, 외부 전력 없이 작동 가능한 자가발전 무선 이산화탄소 모니터링 시스템을 개발했다.
이번 시스템의 핵심은 산업 장비나 배관에서 발생하는 진동(20~4000㎛ 진폭, 0-300 Hz 주파수 범위)을 전기로 바꾸는 ‘관성 구동(Inertia-driven) 마찰전기 나노발전기(Triboelectric Nanogenerator, TENG)’이다. 이를 통해 배터리 없이도 이산화탄소 농도를 주기적으로 측정하고 무선으로 전송할 수 있다.
연구팀은 4단 적층 구조의 관성 구동 마찰전기 나노발전기(TENG)에 탄성 스프링을 결합해 미세 진동을 증폭시키고 공진 현상을 유도, 13Hz, 0.56g의 가속도 조건에서 0.5㎽의 전력을 안정적으로 생산하는 데 성공했다. 생산된 전력은 이산화탄소 센서와 저전력 블루투스 통신 시스템을 구동하는 데 사용됐다.
권경하 교수는 “효율적인 환경 모니터링을 위해서는 전원 제약 없이 지속적으로 작동 가능한 시스템이 필수”라며, “이번 연구에서는 관성 구동 마찰전기 나노발전기(TENG)로부터 생성된 에너지를 바탕으로 주기적으로 이산화탄소 농도를 측정하고 무선으로 전송할 수 있는 자가발전 시스템을 구현했다”고 설명했다.
이어 “이 기술은 향후 다양한 센서를 통합한 자가발전형 환경 모니터링 플랫폼의 기반 기술로 활용될 수 있을 것”이라고 덧붙였다.
이번 연구 결과는 우리 대학 석사과정 장규림 학생과 중앙대 석사과정 다니엘 마나예 티루네(Daniel Manaye Tiruneh) 학생이 공동 제 1저자로 국제 저명 학술지 `나노 에너지(Nano Energy) (IF 16.8)'에 6월 1일자로 게재됐다.
※논문명 : Highly compact inertia-driven triboelectric nanogenerator for self-powered wireless CO2 monitoring via fine-vibration harvesting,
※DOI: https://doi.org/10.1016/j.nanoen.2025.110872
이번 연구는 사우디 아람코-KAIST CO2 관리 센터의 지원을 받아 수행됐다.
2025.06.09 조회수 2997
배터리 없이 이산화탄소 실시간 모니터링 성공
기후 변화와 지구온난화를 막기 위해서는 이산화탄소(CO2)가 ‘얼마나’ 배출되고 있는지를 정확히 파악하는 것이 핵심이다. 이를 가능하게 하는 것이 바로 이산화탄소 모니터링 기술이다. 최근 한국 연구진이 외부 전력 없이도 이산화탄소 농도를 실시간 측정하고 무선으로 전송할 수 있는 시스템을 개발해 환경 모니터링 기술의 새로운 가능성을 열었다.
우리 대학 전기및전자공학부 권경하 교수 연구팀이 중앙대학교 류한준 교수팀과 공동연구를 통해, 주변의 미세 진동 에너지를 수확해 이산화탄소 농도를 주기적으로 측정할 수 있는 자가발전형 무선 모니터링 시스템을 개발했다고 9일 밝혔다.
지구온난화의 주요 원인인 이산화탄소 배출은 산업계의 지속가능성 평가 지표로 자리 잡고 있으며, 유럽연합(EU)은 이미 공장 배출량 규제를 도입한 상태다. 이러한 규제 흐름에 따라, 효율적이고 지속 가능한 이산화탄소 모니터링 시스템은 환경 관리와 산업 공정 제어에 필수적인 요소로 주목받고 있다.
그러나 기존 이산화탄소 모니터링 시스템은 대부분 배터리나 유선 전원에 의존하기 때문에 설치와 유지보수에 제약이 따른다. 연구팀은 이 문제를 해결하기 위해, 외부 전력 없이 작동 가능한 자가발전 무선 이산화탄소 모니터링 시스템을 개발했다.
이번 시스템의 핵심은 산업 장비나 배관에서 발생하는 진동(20~4000㎛ 진폭, 0-300 Hz 주파수 범위)을 전기로 바꾸는 ‘관성 구동(Inertia-driven) 마찰전기 나노발전기(Triboelectric Nanogenerator, TENG)’이다. 이를 통해 배터리 없이도 이산화탄소 농도를 주기적으로 측정하고 무선으로 전송할 수 있다.
연구팀은 4단 적층 구조의 관성 구동 마찰전기 나노발전기(TENG)에 탄성 스프링을 결합해 미세 진동을 증폭시키고 공진 현상을 유도, 13Hz, 0.56g의 가속도 조건에서 0.5㎽의 전력을 안정적으로 생산하는 데 성공했다. 생산된 전력은 이산화탄소 센서와 저전력 블루투스 통신 시스템을 구동하는 데 사용됐다.
권경하 교수는 “효율적인 환경 모니터링을 위해서는 전원 제약 없이 지속적으로 작동 가능한 시스템이 필수”라며, “이번 연구에서는 관성 구동 마찰전기 나노발전기(TENG)로부터 생성된 에너지를 바탕으로 주기적으로 이산화탄소 농도를 측정하고 무선으로 전송할 수 있는 자가발전 시스템을 구현했다”고 설명했다.
이어 “이 기술은 향후 다양한 센서를 통합한 자가발전형 환경 모니터링 플랫폼의 기반 기술로 활용될 수 있을 것”이라고 덧붙였다.
이번 연구 결과는 우리 대학 석사과정 장규림 학생과 중앙대 석사과정 다니엘 마나예 티루네(Daniel Manaye Tiruneh) 학생이 공동 제 1저자로 국제 저명 학술지 `나노 에너지(Nano Energy) (IF 16.8)'에 6월 1일자로 게재됐다.
※논문명 : Highly compact inertia-driven triboelectric nanogenerator for self-powered wireless CO2 monitoring via fine-vibration harvesting,
※DOI: https://doi.org/10.1016/j.nanoen.2025.110872
이번 연구는 사우디 아람코-KAIST CO2 관리 센터의 지원을 받아 수행됐다.
2025.06.09 조회수 2997 -
 온도에 반응해 말랑·딱딱 변하는 전자잉크 나왔다
스마트폰 같은 딱딱한 전자기기는 안정적인 성능을 제공하지만 착용시 불편함을 주는 반면, 얇고 유연한 웨어러블 기기는 착용감은 뛰어나지만 부드러운 특성 때문에 정밀한 조작에 한계가 있다. 국내 연구진이 온도에 따라 딱딱함과 부드러움을 자유자재로 전환할 수 있는‘액체금속 전자잉크’를 개발해, 가변강성을 갖춘 전자기기의 새로운 패러다임을 열고 있다.
우리 대학 전기및전자공학부 정재웅 교수 연구팀이 서울대 박성준 교수 연구팀, 우리 대학 신소재공학과 스티브 박 교수 연구팀과 공동연구를 통해, 상온에서 마이크로 스케일(머리카락보다 얇은 구조)의 미세 선폭 회로 인쇄가 가능하고 온도에 따라 딱딱함과 부드러움을 자유자재로 조절할 수 있는 액체금속 전자잉크를 개발했다고 4일 밝혔다.
연구팀이 개발한 전자잉크는 정밀한 인쇄가 가능한 물성과 우수한 전기전도성을 동시에 갖추고 있으며, 딱딱함과 부드러움을 자유자재로 조절할 수 있는 전자소자를 상온에서 정밀 제작할 수 있는 획기적인 기술이다.
이 전자잉크는 상용 인쇄회로 기판(PCB) 수준의 복잡한 고해상도 다층 회로 인쇄가 가능하며, 완성된 전자기기는 온도에 반응해 딱딱한 형태를 유연하게 변화시킬 수 있다.
연구팀은 기존 전자기기의 고정된 형태의 한계를 극복하기 위해 체온 근처(29.8 ℃)에서 녹는 액체금속 갈륨에 주목했다. 갈륨은 고체 상태에서는 매우 단단하지만 녹으면 부드러운 액체가 돼 큰 폭의 강성 변화가 가능하다. 하지만 기존 갈륨은 물방울처럼 뭉치려는 성질(높은 표면장력)과 액체 상태에서의 불안정성 때문에 정밀한 회로 제작이 어려웠고, 제조 과정에서 원치 않는 상변화가 일어나는 문제가 있었다.
이러한 갈륨의 한계를 극복하기 위해 산성도(pH) 제어 기반 액체금속 전자 잉크 프린팅 기술을 개발했다.
먼저, 마이크로 크기의 갈륨 입자를 디메틸 설폭사이드(Dimethyl Sulfoxide, 이하 DMSO)라는 중성 용매에 친수성 폴리우레탄 고분자와 함께 섞어 전자 잉크를 제작했다. 이때 DMSO 용매의 중성 상태 덕분에 갈륨 입자들이 고분자 매트릭스에 골고루 분산된 안정적인 고점성 잉크가 형성되며, 이를 통해 상온에서 고해상도 회로 인쇄가 가능해진다.
그리고 인쇄 후에는 가열 과정에서 DMSO 용매가 분해되면서 산성 물질을 생성하고, 이 산성 환경에서 갈륨 입자들 표면의 산화막이 제거돼 입자들이 물리적으로 연결되면서 전기가 통하고 강성을 조절할 수 있는 회로가 형성된다.
연구팀은 이러한 2단계 공정을 통해 상온에서는 안정적인 인쇄가 가능하면서도 완성 후에는 우수한 전기전도성과 가변강성 특성을 갖는 전자소자를 구현할 수 있었다.
개발된 전자잉크는 머리카락 굵기의 절반 (약 50μm)인 미세 선폭으로 정밀한 회로를 인쇄할 수 있으며, 우수한 전기전도도(2.27×10⁶ S/m)와 함께 1,465배나 되는 강성 조절 비율을 제공한다. 이는 플라스틱처럼 딱딱한 상태에서 고무처럼 말랑한 상태까지 자유자재로 변할 수 있음을 뜻한다.
또한 스크린 프린팅, 딥 코팅 등 기존 인쇄 방법들과 호환돼 고해상 대면적 회로 제작은 물론 복잡한 3차원 형태의 다양한 전자기기 제작을 가능하게 한다.
연구팀은 이 기술을 활용해 평상시에는 딱딱한 휴대용 전자기기로 사용하다가 몸에 착용하면 부드러운 웨어러블 헬스케어 기기로 변환되는 가변형 다목적 기기를 개발했다. 뿐만 아니라, 수술 시에는 딱딱한 상태로 정밀한 조작과 뇌 삽입이 가능하지만 뇌 조직 내에서는 부드럽게 변해 조직 내 염증반응을 최소화하는 뇌 탐침을 구현함으로써 이식용 소자로서의 활용 가능성도 입증했다.
정재웅 교수는 “전자 잉크 용매의 산성도 조절을 통해 갈륨 입자들을 전기·기계적 연결하는 독창적 기술로 액체금속 프린팅의 고질적인 문제를 해결하고 상온에서 초정밀 고해상 회로 제작을 가능하게 한 것이 이번 연구의 핵심”이라며 “하나의 기기가 상황에 따라 딱딱한 상태와 부드러운 상태로 자유자재로 변환될 수 있어 다목적 전자기기, 의료 기술, 로봇 분야 등에서 다양한 응용이 가능할 것”이라고 말했다.
전기및전자공학부 이시목 박사과정 학생과 부산대 이건희 교수가 공동 제1 저자로 참여한 이번 연구는 국제 학술지 ‘사이언스 어드밴시스(Science Advances)’에 5월 30일 字에 게재됐다.
(논문명 : Phase-Change Metal Ink with pH-Controlled Chemical Sintering for Versatile and Scalable Fabrication of Variable Stiffness Electronics, DOI/10.1126/sciadv.adv4921)
한편 이번 연구는 과학기술정보통신부에서 추진하는 한국연구재단 중견연구지원사업, 기초연구실지원사업, 보스턴-코리아 공동연구 프로젝트, BK21 FOUR 사업의 지원을 받아 수행됐다.
2025.06.04 조회수 2667
온도에 반응해 말랑·딱딱 변하는 전자잉크 나왔다
스마트폰 같은 딱딱한 전자기기는 안정적인 성능을 제공하지만 착용시 불편함을 주는 반면, 얇고 유연한 웨어러블 기기는 착용감은 뛰어나지만 부드러운 특성 때문에 정밀한 조작에 한계가 있다. 국내 연구진이 온도에 따라 딱딱함과 부드러움을 자유자재로 전환할 수 있는‘액체금속 전자잉크’를 개발해, 가변강성을 갖춘 전자기기의 새로운 패러다임을 열고 있다.
우리 대학 전기및전자공학부 정재웅 교수 연구팀이 서울대 박성준 교수 연구팀, 우리 대학 신소재공학과 스티브 박 교수 연구팀과 공동연구를 통해, 상온에서 마이크로 스케일(머리카락보다 얇은 구조)의 미세 선폭 회로 인쇄가 가능하고 온도에 따라 딱딱함과 부드러움을 자유자재로 조절할 수 있는 액체금속 전자잉크를 개발했다고 4일 밝혔다.
연구팀이 개발한 전자잉크는 정밀한 인쇄가 가능한 물성과 우수한 전기전도성을 동시에 갖추고 있으며, 딱딱함과 부드러움을 자유자재로 조절할 수 있는 전자소자를 상온에서 정밀 제작할 수 있는 획기적인 기술이다.
이 전자잉크는 상용 인쇄회로 기판(PCB) 수준의 복잡한 고해상도 다층 회로 인쇄가 가능하며, 완성된 전자기기는 온도에 반응해 딱딱한 형태를 유연하게 변화시킬 수 있다.
연구팀은 기존 전자기기의 고정된 형태의 한계를 극복하기 위해 체온 근처(29.8 ℃)에서 녹는 액체금속 갈륨에 주목했다. 갈륨은 고체 상태에서는 매우 단단하지만 녹으면 부드러운 액체가 돼 큰 폭의 강성 변화가 가능하다. 하지만 기존 갈륨은 물방울처럼 뭉치려는 성질(높은 표면장력)과 액체 상태에서의 불안정성 때문에 정밀한 회로 제작이 어려웠고, 제조 과정에서 원치 않는 상변화가 일어나는 문제가 있었다.
이러한 갈륨의 한계를 극복하기 위해 산성도(pH) 제어 기반 액체금속 전자 잉크 프린팅 기술을 개발했다.
먼저, 마이크로 크기의 갈륨 입자를 디메틸 설폭사이드(Dimethyl Sulfoxide, 이하 DMSO)라는 중성 용매에 친수성 폴리우레탄 고분자와 함께 섞어 전자 잉크를 제작했다. 이때 DMSO 용매의 중성 상태 덕분에 갈륨 입자들이 고분자 매트릭스에 골고루 분산된 안정적인 고점성 잉크가 형성되며, 이를 통해 상온에서 고해상도 회로 인쇄가 가능해진다.
그리고 인쇄 후에는 가열 과정에서 DMSO 용매가 분해되면서 산성 물질을 생성하고, 이 산성 환경에서 갈륨 입자들 표면의 산화막이 제거돼 입자들이 물리적으로 연결되면서 전기가 통하고 강성을 조절할 수 있는 회로가 형성된다.
연구팀은 이러한 2단계 공정을 통해 상온에서는 안정적인 인쇄가 가능하면서도 완성 후에는 우수한 전기전도성과 가변강성 특성을 갖는 전자소자를 구현할 수 있었다.
개발된 전자잉크는 머리카락 굵기의 절반 (약 50μm)인 미세 선폭으로 정밀한 회로를 인쇄할 수 있으며, 우수한 전기전도도(2.27×10⁶ S/m)와 함께 1,465배나 되는 강성 조절 비율을 제공한다. 이는 플라스틱처럼 딱딱한 상태에서 고무처럼 말랑한 상태까지 자유자재로 변할 수 있음을 뜻한다.
또한 스크린 프린팅, 딥 코팅 등 기존 인쇄 방법들과 호환돼 고해상 대면적 회로 제작은 물론 복잡한 3차원 형태의 다양한 전자기기 제작을 가능하게 한다.
연구팀은 이 기술을 활용해 평상시에는 딱딱한 휴대용 전자기기로 사용하다가 몸에 착용하면 부드러운 웨어러블 헬스케어 기기로 변환되는 가변형 다목적 기기를 개발했다. 뿐만 아니라, 수술 시에는 딱딱한 상태로 정밀한 조작과 뇌 삽입이 가능하지만 뇌 조직 내에서는 부드럽게 변해 조직 내 염증반응을 최소화하는 뇌 탐침을 구현함으로써 이식용 소자로서의 활용 가능성도 입증했다.
정재웅 교수는 “전자 잉크 용매의 산성도 조절을 통해 갈륨 입자들을 전기·기계적 연결하는 독창적 기술로 액체금속 프린팅의 고질적인 문제를 해결하고 상온에서 초정밀 고해상 회로 제작을 가능하게 한 것이 이번 연구의 핵심”이라며 “하나의 기기가 상황에 따라 딱딱한 상태와 부드러운 상태로 자유자재로 변환될 수 있어 다목적 전자기기, 의료 기술, 로봇 분야 등에서 다양한 응용이 가능할 것”이라고 말했다.
전기및전자공학부 이시목 박사과정 학생과 부산대 이건희 교수가 공동 제1 저자로 참여한 이번 연구는 국제 학술지 ‘사이언스 어드밴시스(Science Advances)’에 5월 30일 字에 게재됐다.
(논문명 : Phase-Change Metal Ink with pH-Controlled Chemical Sintering for Versatile and Scalable Fabrication of Variable Stiffness Electronics, DOI/10.1126/sciadv.adv4921)
한편 이번 연구는 과학기술정보통신부에서 추진하는 한국연구재단 중견연구지원사업, 기초연구실지원사업, 보스턴-코리아 공동연구 프로젝트, BK21 FOUR 사업의 지원을 받아 수행됐다.
2025.06.04 조회수 2667 -
 금융 필수 보안 소프트웨어가 해킹 악용 가능성 밝혀
우리나라는 금융 보안 소프트웨어 설치를 의무화한 유일한 국가다. 이것이 오히려 보안 위협에 취약할 수도 있다는 우려가 국내 연구진에 의해 밝혀졌다. KAIST 연구진은 안전한 금융 환경을 위한 현재 복잡하고 위험한 보안 프로그램을 강제로 설치하는 방식 대신, 웹사이트와 인터넷 브라우저에서 원래 설정한 안전한 규칙과 웹 표준을 따르는 ‘근본적 전환’이 필요하다고 설명했다.
우리 대학 전기및전자공학부 김용대·윤인수 교수 공동 연구팀이 고려대 김승주 교수팀, 성균관대 김형식 교수팀, 보안 전문기업 티오리(Theori) 소속 연구진이 공동연구를 통해, 한국 금융보안 소프트웨어의 구조적 취약점을 체계적으로 분석한 연구 결과에 대해 2일 밝혔다.
연구진은 북한의 사이버 공격 사례에서 왜 한국의 보안 소프트웨어가 주요 표적이 되는지에 주목했다. 분석 결과, 해당 소프트웨어들이 설계상의 구조적 결함과 구현상 취약점을 동시에 내포하고 있음이 드러났다. 특히 문제는, 한국에서는 금융 및 공공서비스 이용 시 이러한 보안 프로그램의 설치를 의무화하고 있다는 점이다.
이는 전 세계적으로도 유례가 없는 정책이다. 연구팀은 국내 주요 금융기관과 공공기관에서 사용 중인 7종의 주요 보안 프로그램(Korea Security Applications, 이하 ‘KSA 프로그램’)을 분석해 총 19건의 심각한 보안 취약점을 발견했다. 주요 취약점은 ▲키보드 입력 탈취 ▲중간자 공격(MITM) ▲공인인증서 유출 ▲원격 코드 실행(RCE) ▲사용자 식별 및 추적 이다.
일부 취약점은 연구진의 제보로 패치됐으나, 전체 보안 생태계를 관통하는 근본적 설계 취약점은 여전히 해결되지 않은 상태다. 연구진은 "이러한 보안 소프트웨어는 사용자의 안전을 위한 도구가 되어야 함에도 오히려 공격의 통로로 악용될 수 있다”며, 보안의 근본적 패러다임 전환이 필요하다고 강조했다.
연구팀은 국내 금융보안 소프트웨어들이 웹 브라우저의 보안 구조를 우회해 민감한 시스템 기능을 수행하도록 설계됐다고 지적했다. 브라우저는 원칙적으로 외부 웹사이트가 시스템 내부 파일 등 민감 정보에 접근하지 못하도록 제한하지만, KSA는 키보드 보안, 방화벽, 인증서 저장으로 구성된 이른바 ‘보안 3종 세트’를 유지하기 위해 루프백 통신, 외부 프로그램 호출, 비표준 API 활용 등 브라우저 외부 채널을 통해 이러한 제한을 우회하는 방식을 사용하고 있다.
이러한 방식은 2015년까지는 보안 플러그인 ActiveX를 통해 이뤄졌지만, 보안 취약성과 기술적 한계로 ActiveX 지원이 중단되면서 근본적인 개선이 이뤄질 것으로 기대됐다. 그러나 실제로는 실행파일(.exe)을 활용한 유사한 구조로 대체되면서, 기존의 문제를 반복하는 방식으로 이어졌다. 이로 인해 브라우저 보안 경계를 우회하고, 민감 정보에 직접 접근하는 보안 리스크가 여전히 지속되고 있다.
이러한 설계는 ▲동일 출처 정책(Same-Origin Policy, SOP)* ▲샌드박스** ▲권한 격리*** 등 최신 웹 보안 메커니즘과 정면으로 충돌한다. 연구팀은 실제로 이러한 구조가 새로운 공격 경로로 악용될 수 있음을 실증적으로 확인했다.
*Same-Origin Policy(SOP, 동일 출처 정책): 웹 보안의 핵심 개념 중 하나로, 서로 다른 출처(origin)의 웹 페이지나 스크립트 간에 데이터에 접근하지 못하도록 제한하는 보안 정책
**샌드박스(Sandbox): 보안과 안정성을 위해 시스템 내에서 실행되는 코드나 프로그램의 활동을 제한된 환경 안에 가두는 기술
***권한 격리(Privilege Separation): 시스템 보안을 강화하기 위해, 프로그램이나 프로세스를 여러 부분으로 나누고 각각에 최소한의 권한만 부여하는 보안 설계 방식
연구팀이 전국 400명을 대상으로 실시한 온라인 설문조사 결과, 97.4%가 금융서비스 이용을 위해 KSA를 설치한 경험이 있었으며, 이 중 59.3%는 ‘무엇을 하는 프로그램인지 모른다’고 응답했다. 실제 사용자 PC 48대를 분석한 결과, 1인당 평균 9개의 KSA가 설치돼 있었고 다수는 2022년 이전 버전이었다. 일부는 2019년 버전까지 사용되고 있었다.
김용대 교수는 “문제는 단순한 버그가 아니라, ‘웹은 위험하므로 보호해야 한다’는 브라우저의 보안 철학과 정면으로 충돌하는 구조”라며 “이처럼 구조적으로 안전하지 않은 시스템은 작은 실수도 치명적인 보안 사고로 이어질 수 있다”고 강조했다.
이어 “이제는 비표준 보안 소프트웨어들을 강제로 설치시키는 방식이 아니라, 웹 표준과 브라우저 보안 모델을 따르는 방향으로 전환해야 한다”며, “그렇지 않으면 KSA는 향후에도 국가 차원의 보안 위협의 중심이 될 것”이라고 덧붙였다.
우리 대학 김용대·윤인수 교수, 고려대 김승주 교수, 성균관대 김형식 교수가 연구를 주도했으며, 제1 저자인 윤태식 연구원<(주)티오리/KAIST>을 비롯해 정수환<(주)엔키화이트햇/KAIST>, 이용화<(주)티오리> 연구원이 참여했다. 세계 최고 권위의 보안 학회 중 하나인 ‘유즈닉스 시큐리티 2025(USENIX Security 2025)’에 채택됐다고 2일 밝혔다.
※ 논문명: Too Much of a Good Thing: (In-)Security of Mandatory Security Software for Financial Services in South Korea
※ 논문원문: https://syssec.kaist.ac.kr/pub/2025/Too_Much_Good.pdf
이번 연구는 정보통신기획평가원(IITP)의 RS-2024-00400302, RS-2024-00438686, RS-2022-II221199 과제의 지원을 받아 수행됐다.
데모 동영상 1) https://drive.google.com/file/d/1MAK-fLQ5VEsNtCu0ARpyWuflf1I2yLbv/view?usp=sharing
설명: 피해자가 해킹 사이트에 접속하게 되면 해킹 사이트는 설치된 키보드 보안 프로그램과 통신하여 피해자가 입력하는 키보드 입력을 가로채어 자신에게 전송하도록 설정할 수 있음. 이로 인해 피해자가 입력하는 키보드 입력들이 비밀번호 입력까지도 해커에게 전송됨. 일반적으로 웹 페이지에서 다른 프로그램이나 다른 사이트에 입력하는 키보드 입력을 가로채는 것이 불가능하지만 KSA를 이용해 키보드 입력을 가로챌 수 있음.
데모 동영상 2) https://drive.google.com/file/d/17xrxXuwejYvxbOSHDNLTr9G_vKWI0Lbm/view?usp=sharing
설명: 피해자가 해킹 사이트에 접속하게 되면 해킹 사이트는 KSA와 통신하여 피해자의 PC에 악성 파일을 다운로드 시킬 수 있고, 해당 파일을 이용해 민감한 저장소에 악성 프로그램을 설치할 수 있음. 설치된 악성 프로그램은 피해자가 PC를 재부팅하면 실행되며 해커가 원하는 코드를 임의로 실행할 수 있음. 데모 동영상에서는 단순히 해커가 원하는 코드를 실행할 수 있음을 보이기 위해 계산기 프로그램을 실행하였지만 실제 상황에서는 백도어 등을 해커가 피해자 PC에 설치할 수 있음. 일반적으로 웹페이지에서 시스템에서 동작하는 코드를 실행하는 것은 불가능하지만 KSA의 취약성을 이용해 시스템에서 동작하는 코드를 실행하여 악성 행위를 할 수 있음.
2025.06.02 조회수 5824
금융 필수 보안 소프트웨어가 해킹 악용 가능성 밝혀
우리나라는 금융 보안 소프트웨어 설치를 의무화한 유일한 국가다. 이것이 오히려 보안 위협에 취약할 수도 있다는 우려가 국내 연구진에 의해 밝혀졌다. KAIST 연구진은 안전한 금융 환경을 위한 현재 복잡하고 위험한 보안 프로그램을 강제로 설치하는 방식 대신, 웹사이트와 인터넷 브라우저에서 원래 설정한 안전한 규칙과 웹 표준을 따르는 ‘근본적 전환’이 필요하다고 설명했다.
우리 대학 전기및전자공학부 김용대·윤인수 교수 공동 연구팀이 고려대 김승주 교수팀, 성균관대 김형식 교수팀, 보안 전문기업 티오리(Theori) 소속 연구진이 공동연구를 통해, 한국 금융보안 소프트웨어의 구조적 취약점을 체계적으로 분석한 연구 결과에 대해 2일 밝혔다.
연구진은 북한의 사이버 공격 사례에서 왜 한국의 보안 소프트웨어가 주요 표적이 되는지에 주목했다. 분석 결과, 해당 소프트웨어들이 설계상의 구조적 결함과 구현상 취약점을 동시에 내포하고 있음이 드러났다. 특히 문제는, 한국에서는 금융 및 공공서비스 이용 시 이러한 보안 프로그램의 설치를 의무화하고 있다는 점이다.
이는 전 세계적으로도 유례가 없는 정책이다. 연구팀은 국내 주요 금융기관과 공공기관에서 사용 중인 7종의 주요 보안 프로그램(Korea Security Applications, 이하 ‘KSA 프로그램’)을 분석해 총 19건의 심각한 보안 취약점을 발견했다. 주요 취약점은 ▲키보드 입력 탈취 ▲중간자 공격(MITM) ▲공인인증서 유출 ▲원격 코드 실행(RCE) ▲사용자 식별 및 추적 이다.
일부 취약점은 연구진의 제보로 패치됐으나, 전체 보안 생태계를 관통하는 근본적 설계 취약점은 여전히 해결되지 않은 상태다. 연구진은 "이러한 보안 소프트웨어는 사용자의 안전을 위한 도구가 되어야 함에도 오히려 공격의 통로로 악용될 수 있다”며, 보안의 근본적 패러다임 전환이 필요하다고 강조했다.
연구팀은 국내 금융보안 소프트웨어들이 웹 브라우저의 보안 구조를 우회해 민감한 시스템 기능을 수행하도록 설계됐다고 지적했다. 브라우저는 원칙적으로 외부 웹사이트가 시스템 내부 파일 등 민감 정보에 접근하지 못하도록 제한하지만, KSA는 키보드 보안, 방화벽, 인증서 저장으로 구성된 이른바 ‘보안 3종 세트’를 유지하기 위해 루프백 통신, 외부 프로그램 호출, 비표준 API 활용 등 브라우저 외부 채널을 통해 이러한 제한을 우회하는 방식을 사용하고 있다.
이러한 방식은 2015년까지는 보안 플러그인 ActiveX를 통해 이뤄졌지만, 보안 취약성과 기술적 한계로 ActiveX 지원이 중단되면서 근본적인 개선이 이뤄질 것으로 기대됐다. 그러나 실제로는 실행파일(.exe)을 활용한 유사한 구조로 대체되면서, 기존의 문제를 반복하는 방식으로 이어졌다. 이로 인해 브라우저 보안 경계를 우회하고, 민감 정보에 직접 접근하는 보안 리스크가 여전히 지속되고 있다.
이러한 설계는 ▲동일 출처 정책(Same-Origin Policy, SOP)* ▲샌드박스** ▲권한 격리*** 등 최신 웹 보안 메커니즘과 정면으로 충돌한다. 연구팀은 실제로 이러한 구조가 새로운 공격 경로로 악용될 수 있음을 실증적으로 확인했다.
*Same-Origin Policy(SOP, 동일 출처 정책): 웹 보안의 핵심 개념 중 하나로, 서로 다른 출처(origin)의 웹 페이지나 스크립트 간에 데이터에 접근하지 못하도록 제한하는 보안 정책
**샌드박스(Sandbox): 보안과 안정성을 위해 시스템 내에서 실행되는 코드나 프로그램의 활동을 제한된 환경 안에 가두는 기술
***권한 격리(Privilege Separation): 시스템 보안을 강화하기 위해, 프로그램이나 프로세스를 여러 부분으로 나누고 각각에 최소한의 권한만 부여하는 보안 설계 방식
연구팀이 전국 400명을 대상으로 실시한 온라인 설문조사 결과, 97.4%가 금융서비스 이용을 위해 KSA를 설치한 경험이 있었으며, 이 중 59.3%는 ‘무엇을 하는 프로그램인지 모른다’고 응답했다. 실제 사용자 PC 48대를 분석한 결과, 1인당 평균 9개의 KSA가 설치돼 있었고 다수는 2022년 이전 버전이었다. 일부는 2019년 버전까지 사용되고 있었다.
김용대 교수는 “문제는 단순한 버그가 아니라, ‘웹은 위험하므로 보호해야 한다’는 브라우저의 보안 철학과 정면으로 충돌하는 구조”라며 “이처럼 구조적으로 안전하지 않은 시스템은 작은 실수도 치명적인 보안 사고로 이어질 수 있다”고 강조했다.
이어 “이제는 비표준 보안 소프트웨어들을 강제로 설치시키는 방식이 아니라, 웹 표준과 브라우저 보안 모델을 따르는 방향으로 전환해야 한다”며, “그렇지 않으면 KSA는 향후에도 국가 차원의 보안 위협의 중심이 될 것”이라고 덧붙였다.
우리 대학 김용대·윤인수 교수, 고려대 김승주 교수, 성균관대 김형식 교수가 연구를 주도했으며, 제1 저자인 윤태식 연구원<(주)티오리/KAIST>을 비롯해 정수환<(주)엔키화이트햇/KAIST>, 이용화<(주)티오리> 연구원이 참여했다. 세계 최고 권위의 보안 학회 중 하나인 ‘유즈닉스 시큐리티 2025(USENIX Security 2025)’에 채택됐다고 2일 밝혔다.
※ 논문명: Too Much of a Good Thing: (In-)Security of Mandatory Security Software for Financial Services in South Korea
※ 논문원문: https://syssec.kaist.ac.kr/pub/2025/Too_Much_Good.pdf
이번 연구는 정보통신기획평가원(IITP)의 RS-2024-00400302, RS-2024-00438686, RS-2022-II221199 과제의 지원을 받아 수행됐다.
데모 동영상 1) https://drive.google.com/file/d/1MAK-fLQ5VEsNtCu0ARpyWuflf1I2yLbv/view?usp=sharing
설명: 피해자가 해킹 사이트에 접속하게 되면 해킹 사이트는 설치된 키보드 보안 프로그램과 통신하여 피해자가 입력하는 키보드 입력을 가로채어 자신에게 전송하도록 설정할 수 있음. 이로 인해 피해자가 입력하는 키보드 입력들이 비밀번호 입력까지도 해커에게 전송됨. 일반적으로 웹 페이지에서 다른 프로그램이나 다른 사이트에 입력하는 키보드 입력을 가로채는 것이 불가능하지만 KSA를 이용해 키보드 입력을 가로챌 수 있음.
데모 동영상 2) https://drive.google.com/file/d/17xrxXuwejYvxbOSHDNLTr9G_vKWI0Lbm/view?usp=sharing
설명: 피해자가 해킹 사이트에 접속하게 되면 해킹 사이트는 KSA와 통신하여 피해자의 PC에 악성 파일을 다운로드 시킬 수 있고, 해당 파일을 이용해 민감한 저장소에 악성 프로그램을 설치할 수 있음. 설치된 악성 프로그램은 피해자가 PC를 재부팅하면 실행되며 해커가 원하는 코드를 임의로 실행할 수 있음. 데모 동영상에서는 단순히 해커가 원하는 코드를 실행할 수 있음을 보이기 위해 계산기 프로그램을 실행하였지만 실제 상황에서는 백도어 등을 해커가 피해자 PC에 설치할 수 있음. 일반적으로 웹페이지에서 시스템에서 동작하는 코드를 실행하는 것은 불가능하지만 KSA의 취약성을 이용해 시스템에서 동작하는 코드를 실행하여 악성 행위를 할 수 있음.
2025.06.02 조회수 5824 -
 음악 창작 돕는 작곡 AI 동료 ‘어뮤즈’ 공개
음악 창작자가 초기 아이디어를 생각하거나 창작 중간 막힐 때, 이를 같이 해결해 주고 다양한 음악적 방향 탐색에 실질적인 도움을 주는 동료가 있다면 얼마나 좋을까? KAIST 연구진이 이런 음악 창작을 돕는 동료 작가와 같은 AI 기술을 개발했다.
KAIST(총장 이광형)는 전기및전자공학부 이성주 교수 연구팀이 AI 기반 음악 창작 지원 시스템 어뮤즈(Amuse)를 개발하였다. 이 연구 결과는 4월 26일부터 5월 1일까지 일본 요코하마에서 열린 인간-컴퓨터 상호작용 분야 세계 최고 권위의 국제학술대회인 CHI(ACM Conference on Human Factors in Computing Systems)에서 전체 논문 중 상위 1%에게만 수여되는 최우수 논문상(Best Paper Award)을 수상했다고 7일 밝혔다.
이성주 교수 연구팀이 개발한 어뮤즈(Amuse) 시스템은 텍스트, 이미지, 오디오와 같은 다양한 형식의 영감을 입력하면 이를 화성 구조(코드 진행)로 변환해 작곡을 지원해 주는 AI 기반 시스템이다.
예를 들어, 사용자가 ‘따뜻한 여름 해변의 기억’과 같은 문구나 이미지, 사운드 클립을 입력하면, 어뮤즈는 해당 영감에 어울리는 코드 진행을 자동으로 생성해 제안한다.
기존의 생성 AI와 달리, 어뮤즈는 사용자의 창작 흐름을 존중하고, AI의 제안을 유연하게 통합·수정할 수 있는 상호작용 방식을 통해 창의적 탐색을 자연스럽게 유도한다는 점에서 차별성을 갖는다.
어뮤즈 시스템의 핵심 기술은 대형 언어 모델의 이용해 사용자의 영감으로 프롬프트에 입력한 글자 따라 이에 어울리는 음악 코드를 생성하고, 실제 음악 데이터를 학습한 AI 모델이 부자연스럽거나 어색한 결과는 걸러내는(리젝션 샘플링) 과정을 거쳐 결합한 두 가지 방법을 자연스럽게 이어 재현하는 하이브리드 생성 방식이다.
연구팀은 실제 뮤지션들을 대상으로 한 사용자 연구를 수행하여, 어뮤즈가 단순한 음악 생성 AI가 아닌, 사람과 AI가 협업하는 창작 동반자(Co-Creative AI)로서의 가능성이 높다는 평가를 받았다.
KAIST 전기 및 전자공학부 박사과정 김예원, 이성주 교수, 카네기 멜런 대학의 크리스 도너휴(Chris Donahue) 교수가 참여한 해당 논문은 학계 및 산업계 모두의 창의적 AI 시스템 설계의 가능성을 보여주었다.
※ 논문명 : Amuse: Human-AI Collaborative Songwriting with Multimodal Inspirations DOI : https://doi.org/10.1145/3706598.3713818
※ 연구 데모 영상: https://youtu.be/udilkRSnftI?si=FNXccC9EjxHOCrm1
※ 연구 홈페이지: https://nmsl.kaist.ac.kr/projects/amuse/
이성주 교수는 “ 최근 생성형 AI 기술은 저작권이 있는 콘텐츠를 그대로 모방하여 창작자의 저작권을 침해하거나, 창작자의 의도와는 무관하게 일방향으로 결과물을 생성한다는 점에서 우려를 낳고 있다. 이에 연구팀은 이러한 흐름에 문제 의식을 가지고, 창작자가 실제로 필요로 하는 것이 무엇인지에 주목하며 창작자 중심의 AI 시스템 설계에 주안점을 두었다.”라고 말했다.
이어 ”어뮤즈는 창작자의 주도권을 유지한 채, 인공지능과의 협업 가능성을 탐색하는 시도로, 향후 음악 창작 도구와 생성형 AI 시스템의 개발에 있어 보다 창작자 친화적인 방향을 제시하는 출발점이 될 것으로 기대된다.“라고 설명했다.
이 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원을 받아 수행되었다.(RS-2024-00337007)
2025.05.07 조회수 4730
음악 창작 돕는 작곡 AI 동료 ‘어뮤즈’ 공개
음악 창작자가 초기 아이디어를 생각하거나 창작 중간 막힐 때, 이를 같이 해결해 주고 다양한 음악적 방향 탐색에 실질적인 도움을 주는 동료가 있다면 얼마나 좋을까? KAIST 연구진이 이런 음악 창작을 돕는 동료 작가와 같은 AI 기술을 개발했다.
KAIST(총장 이광형)는 전기및전자공학부 이성주 교수 연구팀이 AI 기반 음악 창작 지원 시스템 어뮤즈(Amuse)를 개발하였다. 이 연구 결과는 4월 26일부터 5월 1일까지 일본 요코하마에서 열린 인간-컴퓨터 상호작용 분야 세계 최고 권위의 국제학술대회인 CHI(ACM Conference on Human Factors in Computing Systems)에서 전체 논문 중 상위 1%에게만 수여되는 최우수 논문상(Best Paper Award)을 수상했다고 7일 밝혔다.
이성주 교수 연구팀이 개발한 어뮤즈(Amuse) 시스템은 텍스트, 이미지, 오디오와 같은 다양한 형식의 영감을 입력하면 이를 화성 구조(코드 진행)로 변환해 작곡을 지원해 주는 AI 기반 시스템이다.
예를 들어, 사용자가 ‘따뜻한 여름 해변의 기억’과 같은 문구나 이미지, 사운드 클립을 입력하면, 어뮤즈는 해당 영감에 어울리는 코드 진행을 자동으로 생성해 제안한다.
기존의 생성 AI와 달리, 어뮤즈는 사용자의 창작 흐름을 존중하고, AI의 제안을 유연하게 통합·수정할 수 있는 상호작용 방식을 통해 창의적 탐색을 자연스럽게 유도한다는 점에서 차별성을 갖는다.
어뮤즈 시스템의 핵심 기술은 대형 언어 모델의 이용해 사용자의 영감으로 프롬프트에 입력한 글자 따라 이에 어울리는 음악 코드를 생성하고, 실제 음악 데이터를 학습한 AI 모델이 부자연스럽거나 어색한 결과는 걸러내는(리젝션 샘플링) 과정을 거쳐 결합한 두 가지 방법을 자연스럽게 이어 재현하는 하이브리드 생성 방식이다.
연구팀은 실제 뮤지션들을 대상으로 한 사용자 연구를 수행하여, 어뮤즈가 단순한 음악 생성 AI가 아닌, 사람과 AI가 협업하는 창작 동반자(Co-Creative AI)로서의 가능성이 높다는 평가를 받았다.
KAIST 전기 및 전자공학부 박사과정 김예원, 이성주 교수, 카네기 멜런 대학의 크리스 도너휴(Chris Donahue) 교수가 참여한 해당 논문은 학계 및 산업계 모두의 창의적 AI 시스템 설계의 가능성을 보여주었다.
※ 논문명 : Amuse: Human-AI Collaborative Songwriting with Multimodal Inspirations DOI : https://doi.org/10.1145/3706598.3713818
※ 연구 데모 영상: https://youtu.be/udilkRSnftI?si=FNXccC9EjxHOCrm1
※ 연구 홈페이지: https://nmsl.kaist.ac.kr/projects/amuse/
이성주 교수는 “ 최근 생성형 AI 기술은 저작권이 있는 콘텐츠를 그대로 모방하여 창작자의 저작권을 침해하거나, 창작자의 의도와는 무관하게 일방향으로 결과물을 생성한다는 점에서 우려를 낳고 있다. 이에 연구팀은 이러한 흐름에 문제 의식을 가지고, 창작자가 실제로 필요로 하는 것이 무엇인지에 주목하며 창작자 중심의 AI 시스템 설계에 주안점을 두었다.”라고 말했다.
이어 ”어뮤즈는 창작자의 주도권을 유지한 채, 인공지능과의 협업 가능성을 탐색하는 시도로, 향후 음악 창작 도구와 생성형 AI 시스템의 개발에 있어 보다 창작자 친화적인 방향을 제시하는 출발점이 될 것으로 기대된다.“라고 설명했다.
이 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원을 받아 수행되었다.(RS-2024-00337007)
2025.05.07 조회수 4730 -
 외계행성 감지 중적외선 광검출기 혁신, 환경·의료 개척
미국 항공우주국(NASA)의 제임스웹 우주망원경(JWST)은 중적외선 스펙트럼을 활용해 외계 행성 대기의 수증기, 이산화황 등 분자 성분을 정밀하게 분석하고 있다. 이처럼 각 분자가 ‘지문’처럼 고유한 패턴을 나타내는 중적외선 분석의 핵심은, 아주 약한 빛의 세기까지 정밀하게 측정할 수 있는 고감도 광검출기 기술이다. 최근 KAIST 연구진이 중적외선 스펙트럼의 넓은 영역을 감지할 수 있는 혁신적 광검출기 기술을 개발하며 주목을 받고 있다.
우리 대학 전기및전자공학부 김상현 교수팀이 상온에서 안정적으로 동작하는 중적외선 광검출기 기술을 개발하고, 이를 통해 초소형 광학 센서 상용화에 새로운 전환점을 마련했다고 27일 밝혔다.
이번에 개발된 광검출기는 기존 실리콘(Silicon) 기반 CMOS 공정을 활용해 저비용 대량 생산이 가능하며, 상온에서 안정적으로 동작하는 것이 특징이다. 특히 연구팀은 이 광검출기를 적용한 초소형·초박형 광학 센서를 이용해 이산화탄소(CO2) 가스를 실시간으로 검출하는 데 성공, 환경 모니터링 및 유해가스 분석 등 다양한 응용 가능성을 입증했다.
기존 중적외선 광검출기는 상온에서의 높은 열적 잡음(Thermal noise)으로 인해 일반적으로 냉각 시스템이 요구된다. 이러한 냉각 시스템은 장비의 크기와 비용을 증가시켜, 센서의 소형화 및 휴대용 기기 응용을 어렵게 만든다. 또한, 기존 중적외선 광검출기는 실리콘 기반 CMOS 공정과 호환되지 않아 대량생산이 어렵고 상용화가 제한됐다.
이에 연구팀은 실리콘과 같은 주기율표 4족 원소인 저마늄(Germanium) 반도체를 기반으로 한 광학 플랫폼을 활용해, 넓은 대역의 중적외선 검출 성능을 확보하면서도 동시에 상온에서 안정적으로 동작할 수 있는 새로운 형태의 도파로형(waveguide-integrated) 광검출기를 개발했다.
‘도파로’란 빛을 특정한 경로로 손실 없이 효과적으로 유도하는 구조물을 의미한다. 온-칩(on-chip) 상에서 다양한 기능의 광학 회로를 구현하기 위해서는 도파로형 광검출기를 포함해 도파로를 기반으로 하는 광학 소자의 개발이 필수적으로 요구된다.
이번 기술은 기존에 광검출기 동작에 일반적으로 활용되는 밴드갭 흡수 원리와는 다르게 볼로미터 효과(Bolometric effect)*를 활용해 중적외선 스펙트럼 영역 전체를 대응할 수 있기 때문에 다양한 종류의 분자들의 실시간 센싱에 범용적으로 활용될 수 있다.
*볼로미터 효과(Bolometric effect): 빛을 흡수하면 온도가 올라가고, 그 온도 변화에 따라 전기적인 신호가 달라지는 원리
연구팀이 개발한 상온 동작 및 CMOS 공정 호환 중적외선 도파로형 광검출기는 기존 중적외선 센서 기술이 가진 냉각 필요성, 대량 생산의 어려움, 높은 비용 문제를 해결하는 혁신적인 기술로 평가된다.
이를 통해 환경 모니터링, 의료 진단, 산업 공정 관리, 국방 및 보안, 스마트 디바이스 등 다양한 응용 분야에 적용 가능하며, 차세대 중적외선 센서 기술의 핵심적인 돌파구를 제공할 것으로 기대된다.
김상현 교수는 “이번 연구는 기존 중적외선 광검출기 기술의 한계를 극복한 새로운 접근 방식이며, 향후 다양한 응용 분야에서 실용화될 가능성이 매우 크다”고 밝혔다. 또한, “특히 CMOS 공정과 호환되는 센서 기술로, 저비용 대량생산이 가능해 차세대 환경 모니터링 시스템, 스마트 제조 현장 등에서 적극 활용될 것”이라고 덧붙였다.
이번 연구 결과는 심준섭 박사(現 하버드대학교 박사후 연구원)가 제1 저자로 참여해 국제 저명 학술지인 ‘빛, 과학과 응용(Light: Science & Applications, JCR 2.9%, IF=20.6)’에 2025년 3월 19일 자 발표됐다. (논문제목: Room-temperature waveguide-integrated photodetector using bolometric effect for mid-infrared spectroscopy applications, https://doi.org/10.1038/s41377-025-01803-3)
한편, 해당 연구는 한국연구재단의 지원을 받아 진행됐다.
2025.03.27 조회수 4068
외계행성 감지 중적외선 광검출기 혁신, 환경·의료 개척
미국 항공우주국(NASA)의 제임스웹 우주망원경(JWST)은 중적외선 스펙트럼을 활용해 외계 행성 대기의 수증기, 이산화황 등 분자 성분을 정밀하게 분석하고 있다. 이처럼 각 분자가 ‘지문’처럼 고유한 패턴을 나타내는 중적외선 분석의 핵심은, 아주 약한 빛의 세기까지 정밀하게 측정할 수 있는 고감도 광검출기 기술이다. 최근 KAIST 연구진이 중적외선 스펙트럼의 넓은 영역을 감지할 수 있는 혁신적 광검출기 기술을 개발하며 주목을 받고 있다.
우리 대학 전기및전자공학부 김상현 교수팀이 상온에서 안정적으로 동작하는 중적외선 광검출기 기술을 개발하고, 이를 통해 초소형 광학 센서 상용화에 새로운 전환점을 마련했다고 27일 밝혔다.
이번에 개발된 광검출기는 기존 실리콘(Silicon) 기반 CMOS 공정을 활용해 저비용 대량 생산이 가능하며, 상온에서 안정적으로 동작하는 것이 특징이다. 특히 연구팀은 이 광검출기를 적용한 초소형·초박형 광학 센서를 이용해 이산화탄소(CO2) 가스를 실시간으로 검출하는 데 성공, 환경 모니터링 및 유해가스 분석 등 다양한 응용 가능성을 입증했다.
기존 중적외선 광검출기는 상온에서의 높은 열적 잡음(Thermal noise)으로 인해 일반적으로 냉각 시스템이 요구된다. 이러한 냉각 시스템은 장비의 크기와 비용을 증가시켜, 센서의 소형화 및 휴대용 기기 응용을 어렵게 만든다. 또한, 기존 중적외선 광검출기는 실리콘 기반 CMOS 공정과 호환되지 않아 대량생산이 어렵고 상용화가 제한됐다.
이에 연구팀은 실리콘과 같은 주기율표 4족 원소인 저마늄(Germanium) 반도체를 기반으로 한 광학 플랫폼을 활용해, 넓은 대역의 중적외선 검출 성능을 확보하면서도 동시에 상온에서 안정적으로 동작할 수 있는 새로운 형태의 도파로형(waveguide-integrated) 광검출기를 개발했다.
‘도파로’란 빛을 특정한 경로로 손실 없이 효과적으로 유도하는 구조물을 의미한다. 온-칩(on-chip) 상에서 다양한 기능의 광학 회로를 구현하기 위해서는 도파로형 광검출기를 포함해 도파로를 기반으로 하는 광학 소자의 개발이 필수적으로 요구된다.
이번 기술은 기존에 광검출기 동작에 일반적으로 활용되는 밴드갭 흡수 원리와는 다르게 볼로미터 효과(Bolometric effect)*를 활용해 중적외선 스펙트럼 영역 전체를 대응할 수 있기 때문에 다양한 종류의 분자들의 실시간 센싱에 범용적으로 활용될 수 있다.
*볼로미터 효과(Bolometric effect): 빛을 흡수하면 온도가 올라가고, 그 온도 변화에 따라 전기적인 신호가 달라지는 원리
연구팀이 개발한 상온 동작 및 CMOS 공정 호환 중적외선 도파로형 광검출기는 기존 중적외선 센서 기술이 가진 냉각 필요성, 대량 생산의 어려움, 높은 비용 문제를 해결하는 혁신적인 기술로 평가된다.
이를 통해 환경 모니터링, 의료 진단, 산업 공정 관리, 국방 및 보안, 스마트 디바이스 등 다양한 응용 분야에 적용 가능하며, 차세대 중적외선 센서 기술의 핵심적인 돌파구를 제공할 것으로 기대된다.
김상현 교수는 “이번 연구는 기존 중적외선 광검출기 기술의 한계를 극복한 새로운 접근 방식이며, 향후 다양한 응용 분야에서 실용화될 가능성이 매우 크다”고 밝혔다. 또한, “특히 CMOS 공정과 호환되는 센서 기술로, 저비용 대량생산이 가능해 차세대 환경 모니터링 시스템, 스마트 제조 현장 등에서 적극 활용될 것”이라고 덧붙였다.
이번 연구 결과는 심준섭 박사(現 하버드대학교 박사후 연구원)가 제1 저자로 참여해 국제 저명 학술지인 ‘빛, 과학과 응용(Light: Science & Applications, JCR 2.9%, IF=20.6)’에 2025년 3월 19일 자 발표됐다. (논문제목: Room-temperature waveguide-integrated photodetector using bolometric effect for mid-infrared spectroscopy applications, https://doi.org/10.1038/s41377-025-01803-3)
한편, 해당 연구는 한국연구재단의 지원을 받아 진행됐다.
2025.03.27 조회수 4068 -
 챗GPT 등 대형 AI모델 학습 최적화 시뮬레이션 개발
최근 챗GPT, 딥시크(DeepSeek) 등 초거대 인공지능(AI) 모델이 다양한 분야에서 활용되며 주목받고 있다. 이러한 대형 언어 모델은 수만 개의 데이터센터용 GPU를 갖춘 대규모 분산 시스템에서 학습되는데, GPT-4의 경우 모델을 학습하는 데 소모되는 비용은 약 1,400억 원에 육박하는 것으로 추산된다. 한국 연구진이 GPU 사용률을 높이고 학습 비용을 절감할 수 있는 최적의 병렬화 구성을 도출하도록 돕는 기술을 개발했다.
우리 대학 전기및전자공학부 유민수 교수 연구팀은 삼성전자 삼성종합기술원과 공동연구를 통해, 대규모 분산 시스템에서 대형 언어 모델(LLM)의 학습 시간을 예측하고 최적화할 수 있는 시뮬레이션 프레임워크(이하 vTrain)를 개발했다고 13일 밝혔다.
대형 언어 모델 학습 효율을 높이려면 최적의 분산 학습 전략을 찾는 것이 필수적이다. 그러나 가능한 전략의 경우의 수가 방대할 뿐 아니라 실제 환경에서 각 전략의 성능을 테스트하는 데는 막대한 비용과 시간이 들어간다.
이에 따라 현재 대형 언어 모델을 학습하는 기업들은 일부 경험적으로 검증된 소수의 전략만을 사용하고 있다. 이는 GPU 활용의 비효율성과 불필요한 비용 증가를 초래하지만, 대규모 시스템을 위한 시뮬레이션 기술이 부족해 기업들이 문제를 효과적으로 해결하지 못하고 있는 상황이다.
이에 유민수 교수 연구팀은 vTrain을 개발해 대형 언어 모델의 학습 시간을 정확히 예측하고, 다양한 분산 병렬화 전략을 빠르게 탐색할 수 있도록 했다.
연구팀은 실제 다중 GPU 환경에서 다양한 대형 언어 모델 학습 시간 실측값과 vTrain의 예측값을 비교한 결과, 단일 노드에서 평균 절대 오차(MAPE) 8.37%, 다중 노드에서 14.73%의 정확도로 학습 시간을 예측할 수 있음을 검증했다.
연구팀은 삼성전자 삼성종합기술원와 공동연구를 진행하여 vTrain 프레임워크와 1,500개 이상의 실제 학습 시간 측정 데이터를 오픈소스로 공개(https://github.com/VIA-Research/vTrain)하여 AI 연구자와 기업이 이를 자유롭게 활용할 수 있도록 했다.
유민수 교수는 “vTrain은 프로파일링 기반 시뮬레이션 기법으로 기존 경험적 방식 대비 GPU 사용률을 높이고 학습 비용을 절감할 수 있는 학습 전략을 탐색하였으며 오픈소스를 공개하였다. 이를 통해 기업들은 초거대 인공지능 모델 학습 비용을 효율적으로 절감할 것이다”라고 말했다.
이 연구 결과는 방제현 박사과정이 제1 저자로 참여하였고 컴퓨터 아키텍처 분야의 최우수 학술대회 중 하나인 미국 전기전자공학회(IEEE)·전산공학회(ACM) 공동 마이크로아키텍처 국제 학술대회(MICRO)에서 지난 11월 발표됐다. (논문제목: vTrain: A Simulation Framework for Evaluating Cost-Effective and Compute-Optimal Large Language Model Training, https://doi.org/10.1109/MICRO61859.2024.00021)
이번 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단, 정보통신기획평가원, 그리고 삼성전자의 지원을 받아 수행되었으며, 과학기술정보통신부 및 정보통신기획평가원의 SW컴퓨팅산업원천기술개발(SW스타랩) 사업으로 연구개발한 결과물이다.
2025.03.13 조회수 4146
챗GPT 등 대형 AI모델 학습 최적화 시뮬레이션 개발
최근 챗GPT, 딥시크(DeepSeek) 등 초거대 인공지능(AI) 모델이 다양한 분야에서 활용되며 주목받고 있다. 이러한 대형 언어 모델은 수만 개의 데이터센터용 GPU를 갖춘 대규모 분산 시스템에서 학습되는데, GPT-4의 경우 모델을 학습하는 데 소모되는 비용은 약 1,400억 원에 육박하는 것으로 추산된다. 한국 연구진이 GPU 사용률을 높이고 학습 비용을 절감할 수 있는 최적의 병렬화 구성을 도출하도록 돕는 기술을 개발했다.
우리 대학 전기및전자공학부 유민수 교수 연구팀은 삼성전자 삼성종합기술원과 공동연구를 통해, 대규모 분산 시스템에서 대형 언어 모델(LLM)의 학습 시간을 예측하고 최적화할 수 있는 시뮬레이션 프레임워크(이하 vTrain)를 개발했다고 13일 밝혔다.
대형 언어 모델 학습 효율을 높이려면 최적의 분산 학습 전략을 찾는 것이 필수적이다. 그러나 가능한 전략의 경우의 수가 방대할 뿐 아니라 실제 환경에서 각 전략의 성능을 테스트하는 데는 막대한 비용과 시간이 들어간다.
이에 따라 현재 대형 언어 모델을 학습하는 기업들은 일부 경험적으로 검증된 소수의 전략만을 사용하고 있다. 이는 GPU 활용의 비효율성과 불필요한 비용 증가를 초래하지만, 대규모 시스템을 위한 시뮬레이션 기술이 부족해 기업들이 문제를 효과적으로 해결하지 못하고 있는 상황이다.
이에 유민수 교수 연구팀은 vTrain을 개발해 대형 언어 모델의 학습 시간을 정확히 예측하고, 다양한 분산 병렬화 전략을 빠르게 탐색할 수 있도록 했다.
연구팀은 실제 다중 GPU 환경에서 다양한 대형 언어 모델 학습 시간 실측값과 vTrain의 예측값을 비교한 결과, 단일 노드에서 평균 절대 오차(MAPE) 8.37%, 다중 노드에서 14.73%의 정확도로 학습 시간을 예측할 수 있음을 검증했다.
연구팀은 삼성전자 삼성종합기술원와 공동연구를 진행하여 vTrain 프레임워크와 1,500개 이상의 실제 학습 시간 측정 데이터를 오픈소스로 공개(https://github.com/VIA-Research/vTrain)하여 AI 연구자와 기업이 이를 자유롭게 활용할 수 있도록 했다.
유민수 교수는 “vTrain은 프로파일링 기반 시뮬레이션 기법으로 기존 경험적 방식 대비 GPU 사용률을 높이고 학습 비용을 절감할 수 있는 학습 전략을 탐색하였으며 오픈소스를 공개하였다. 이를 통해 기업들은 초거대 인공지능 모델 학습 비용을 효율적으로 절감할 것이다”라고 말했다.
이 연구 결과는 방제현 박사과정이 제1 저자로 참여하였고 컴퓨터 아키텍처 분야의 최우수 학술대회 중 하나인 미국 전기전자공학회(IEEE)·전산공학회(ACM) 공동 마이크로아키텍처 국제 학술대회(MICRO)에서 지난 11월 발표됐다. (논문제목: vTrain: A Simulation Framework for Evaluating Cost-Effective and Compute-Optimal Large Language Model Training, https://doi.org/10.1109/MICRO61859.2024.00021)
이번 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단, 정보통신기획평가원, 그리고 삼성전자의 지원을 받아 수행되었으며, 과학기술정보통신부 및 정보통신기획평가원의 SW컴퓨팅산업원천기술개발(SW스타랩) 사업으로 연구개발한 결과물이다.
2025.03.13 조회수 4146