GPT
-
 KAIST develops “FlexGNN,” a graph analysis AI 95 times faster with a single GPU
<(From Left) Donghyoung Han, CTO of GraphAI Co, Ph.D candidate Jeongmin Bae from KAIST, Professor Min-soo Kim from KAIST>
Alongside text-based large language models (LLMs) including ChatGPT, in industrial fields, GNN (Graph Neural Network)-based graph AI models that analyze unstructured data such as financial transactions, stocks, social media, and patient records in graph form are being actively used. However, there is a limitation in that full graph learning—training the entire graph at once—requires massive memory and GPU servers. A KAIST research team has succeeded in developing the world’s highest-performance software technology that can train large-scale GNN models at maximum speed using only a single GPU server.
KAIST (President Kwang Hyung Lee) announced on the 13th that the research team led by Professor Min-Soo Kim of the School of Computing has developed “FlexGNN,” a GNN system that, unlike existing methods using multiple GPU servers, can quickly train and infer large-scale full-graph AI models on a single GPU server. FlexGNN improves training speed by up to 95 times compared to existing technologies.
Recently, in various fields such as climate, finance, medicine, pharmaceuticals, manufacturing, and distribution, there has been a growing number of cases where data is converted into graph form, consisting of nodes and edges, for analysis and prediction.
While the full graph approach, which uses the entire graph for training, achieves higher accuracy, it has the drawback of frequently running out of memory due to the generation of massive intermediate data during training, as well as prolonged training times caused by data communication between multiple servers.
To overcome these problems, FlexGNN performs optimal AI model training on a single GPU server by utilizing SSDs (solid-state drives) and main memory instead of multiple GPU servers.
<Figure (a): This illustrates the typical execution flow of a conventional full-graph GNN training system. All intermediate data generated during training are retained in GPU memory, and computations are performed sequentially without data movement or memory optimization. Consequently, if the GPU memory capacity is exceeded, training becomes infeasible. Additionally, inter-GPU data exchange relies solely on a fixed method (X_rigid), limiting performance and scalability. Figure (b): This depicts an example of the execution flow based on the optimized training execution plan generated by FlexGNN. For each intermediate data, strategies such as retention, offloading, or recomputation are selectively applied. Depending on resource constraints and data size, an appropriate inter-GPU exchange method—either GPU-to-GPU (G2G) or GPU-to-Host (G2H)—is adaptively chosen by the exchange operator (X_adapt). Furthermore, offloading and reloading operations are scheduled to overlap as much as possible with computation, maximizing compute-data movement parallelism. The adaptive exchange operator and various data offloading and reloading operators (R, O) within the figure demonstrate FlexGNN's ability to flexibly control intermediate data management and inter-GPU exchange strategies based on the training execution plan.>
Particularly, through AI query optimization training—which optimizes the quality of database systems—the team developed a new training optimization technology that calculates model parameters, training data, and intermediate data between GPU, main memory, and SSD layers at the optimal timing and method.
As a result, FlexGNN flexibly generates optimal training execution plans according to available resources such as data size, model scale, and GPU memory, thereby achieving high resource efficiency and training speed.
Consequently, it became possible to train GNN models on data far exceeding main memory capacity, and training could be up to 95 times faster even on a single GPU server. In particular, the realization of full-graph AI, capable of more precise analysis than supercomputers in applications such as climate prediction, has become a reality.
Professor Min-Soo Kim of KAIST stated, “As full-graph GNN models are actively used to solve complex problems such as weather prediction and new material discovery, the importance of related technologies is increasing.” He added that “since FlexGNN has dramatically solved the longstanding problems of training scale and speed in graph AI models, we expect it to be widely used in various industries.”
In this research, Jeongmin Bae, a doctoral student in the School of Computing at KAIST, participated as the first author, Donghyoung Han, CTO of GraphAI Co. (founded by Professor Kim) participated as the second author, and Professor Kim served as the corresponding author.
The research results were presented on August 5 at ACM KDD, a world-renowned data mining conference. The FlexGNN technology is also planned to be applied to Grapheye’s graph database solution, GraphOn.
● Paper title: FlexGNN: A High-Performance, Large-Scale Full-Graph GNN System with Best-Effort Training Plan Optimization
● DOI: https://doi.org/10.1145/3711896.3736964
This research was supported by the IITP SW Star Lab and IITP-ITRC of the Ministry of Science and ICT, as well as the mid-level project program of the National Research Foundation of Korea.
2025.08.13 View 13
KAIST develops “FlexGNN,” a graph analysis AI 95 times faster with a single GPU
<(From Left) Donghyoung Han, CTO of GraphAI Co, Ph.D candidate Jeongmin Bae from KAIST, Professor Min-soo Kim from KAIST>
Alongside text-based large language models (LLMs) including ChatGPT, in industrial fields, GNN (Graph Neural Network)-based graph AI models that analyze unstructured data such as financial transactions, stocks, social media, and patient records in graph form are being actively used. However, there is a limitation in that full graph learning—training the entire graph at once—requires massive memory and GPU servers. A KAIST research team has succeeded in developing the world’s highest-performance software technology that can train large-scale GNN models at maximum speed using only a single GPU server.
KAIST (President Kwang Hyung Lee) announced on the 13th that the research team led by Professor Min-Soo Kim of the School of Computing has developed “FlexGNN,” a GNN system that, unlike existing methods using multiple GPU servers, can quickly train and infer large-scale full-graph AI models on a single GPU server. FlexGNN improves training speed by up to 95 times compared to existing technologies.
Recently, in various fields such as climate, finance, medicine, pharmaceuticals, manufacturing, and distribution, there has been a growing number of cases where data is converted into graph form, consisting of nodes and edges, for analysis and prediction.
While the full graph approach, which uses the entire graph for training, achieves higher accuracy, it has the drawback of frequently running out of memory due to the generation of massive intermediate data during training, as well as prolonged training times caused by data communication between multiple servers.
To overcome these problems, FlexGNN performs optimal AI model training on a single GPU server by utilizing SSDs (solid-state drives) and main memory instead of multiple GPU servers.
<Figure (a): This illustrates the typical execution flow of a conventional full-graph GNN training system. All intermediate data generated during training are retained in GPU memory, and computations are performed sequentially without data movement or memory optimization. Consequently, if the GPU memory capacity is exceeded, training becomes infeasible. Additionally, inter-GPU data exchange relies solely on a fixed method (X_rigid), limiting performance and scalability. Figure (b): This depicts an example of the execution flow based on the optimized training execution plan generated by FlexGNN. For each intermediate data, strategies such as retention, offloading, or recomputation are selectively applied. Depending on resource constraints and data size, an appropriate inter-GPU exchange method—either GPU-to-GPU (G2G) or GPU-to-Host (G2H)—is adaptively chosen by the exchange operator (X_adapt). Furthermore, offloading and reloading operations are scheduled to overlap as much as possible with computation, maximizing compute-data movement parallelism. The adaptive exchange operator and various data offloading and reloading operators (R, O) within the figure demonstrate FlexGNN's ability to flexibly control intermediate data management and inter-GPU exchange strategies based on the training execution plan.>
Particularly, through AI query optimization training—which optimizes the quality of database systems—the team developed a new training optimization technology that calculates model parameters, training data, and intermediate data between GPU, main memory, and SSD layers at the optimal timing and method.
As a result, FlexGNN flexibly generates optimal training execution plans according to available resources such as data size, model scale, and GPU memory, thereby achieving high resource efficiency and training speed.
Consequently, it became possible to train GNN models on data far exceeding main memory capacity, and training could be up to 95 times faster even on a single GPU server. In particular, the realization of full-graph AI, capable of more precise analysis than supercomputers in applications such as climate prediction, has become a reality.
Professor Min-Soo Kim of KAIST stated, “As full-graph GNN models are actively used to solve complex problems such as weather prediction and new material discovery, the importance of related technologies is increasing.” He added that “since FlexGNN has dramatically solved the longstanding problems of training scale and speed in graph AI models, we expect it to be widely used in various industries.”
In this research, Jeongmin Bae, a doctoral student in the School of Computing at KAIST, participated as the first author, Donghyoung Han, CTO of GraphAI Co. (founded by Professor Kim) participated as the second author, and Professor Kim served as the corresponding author.
The research results were presented on August 5 at ACM KDD, a world-renowned data mining conference. The FlexGNN technology is also planned to be applied to Grapheye’s graph database solution, GraphOn.
● Paper title: FlexGNN: A High-Performance, Large-Scale Full-Graph GNN System with Best-Effort Training Plan Optimization
● DOI: https://doi.org/10.1145/3711896.3736964
This research was supported by the IITP SW Star Lab and IITP-ITRC of the Ministry of Science and ICT, as well as the mid-level project program of the National Research Foundation of Korea.
2025.08.13 View 13 -
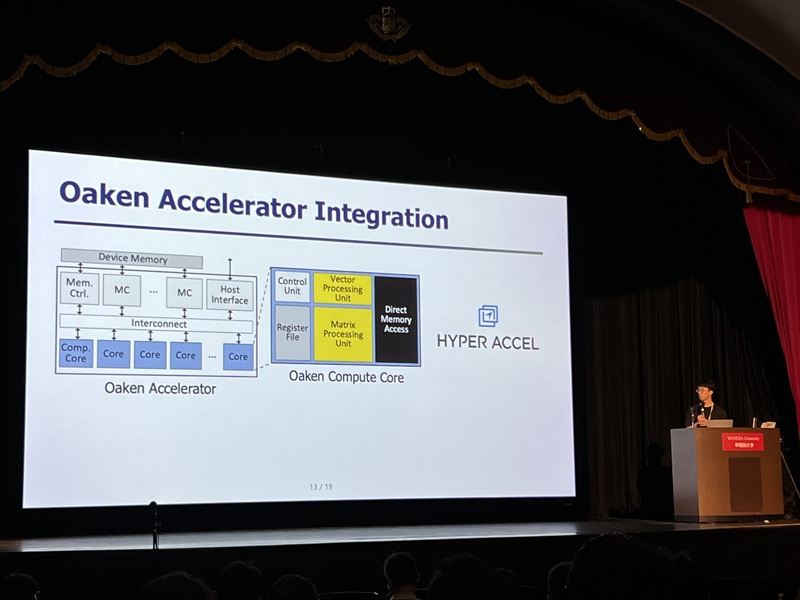 Development of Core NPU Technology to Improve ChatGPT Inference Performance by Over 60%
Latest generative AI models such as OpenAI's ChatGPT-4 and Google's Gemini 2.5 require not only high memory bandwidth but also large memory capacity. This is why generative AI cloud operating companies like Microsoft and Google purchase hundreds of thousands of NVIDIA GPUs. As a solution to address the core challenges of building such high-performance AI infrastructure, Korean researchers have succeeded in developing an NPU (Neural Processing Unit)* core technology that improves the inference performance of generative AI models by an average of over 60% while consuming approximately 44% less power compared to the latest GPUs.
*NPU (Neural Processing Unit): An AI-specific semiconductor chip designed to rapidly process artificial neural networks.
On the 4th, Professor Jongse Park's research team from KAIST School of Computing, in collaboration with HyperAccel Inc. (a startup founded by Professor Joo-Young Kim from the School of Electrical Engineering), announced that they have developed a high-performance, low-power NPU (Neural Processing Unit) core technology specialized for generative AI clouds like ChatGPT.
The technology proposed by the research team has been accepted by the '2025 International Symposium on Computer Architecture (ISCA 2025)', a top-tier international conference in the field of computer architecture.
The key objective of this research is to improve the performance of large-scale generative AI services by lightweighting the inference process, while minimizing accuracy loss and solving memory bottleneck issues. This research is highly recognized for its integrated design of AI semiconductors and AI system software, which are key components of AI infrastructure.
While existing GPU-based AI infrastructure requires multiple GPU devices to meet high bandwidth and capacity demands, this technology enables the configuration of the same level of AI infrastructure using fewer NPU devices through KV cache quantization*. KV cache accounts for most of the memory usage, thereby its quantization significantly reduces the cost of building generative AI clouds.
*KV Cache (Key-Value Cache) Quantization: Refers to reducing the data size in a type of temporary storage space used to improve performance when operating generative AI models (e.g., converting a 16-bit number to a 4-bit number reduces data size by 1/4).
The research team designed it to be integrated with memory interfaces without changing the operational logic of existing NPU architectures. This hardware architecture not only implements the proposed quantization algorithm but also adopts page-level memory management techniques* for efficient utilization of limited memory bandwidth and capacity, and introduces new encoding technique optimized for quantized KV cache.
*Page-level memory management technique: Virtualizes memory addresses, as the CPU does, to allow consistent access within the NPU.
Furthermore, when building an NPU-based AI cloud with superior cost and power efficiency compared to the latest GPUs, the high-performance, low-power nature of NPUs is expected to significantly reduce operating costs.
Professor Jongse Park stated, "This research, through joint work with HyperAccel Inc., found a solution in generative AI inference lightweighting algorithms and succeeded in developing a core NPU technology that can solve the 'memory problem.' Through this technology, we implemented an NPU with over 60% improved performance compared to the latest GPUs by combining quantization techniques that reduce memory requirements while maintaining inference accuracy, and hardware designs optimized for this".
He further emphasized, "This technology has demonstrated the possibility of implementing high-performance, low-power infrastructure specialized for generative AI, and is expected to play a key role not only in AI cloud data centers but also in the AI transformation (AX) environment represented by dynamic, executable AI such as 'Agentic AI'."
This research was presented by Ph.D. student Minsu Kim and Dr. Seongmin Hong from HyperAccel Inc. as co-first authors at the '2025 International Symposium on Computer Architecture (ISCA)' held in Tokyo, Japan, from June 21 to June 25. ISCA, a globally renowned academic conference, received 570 paper submissions this year, with only 127 papers accepted (an acceptance rate of 22.7%).
※Paper Title: Oaken: Fast and Efficient LLM Serving with Online-Offline Hybrid KV Cache Quantization
※DOI: https://doi.org/10.1145/3695053.3731019
Meanwhile, this research was supported by the National Research Foundation of Korea's Excellent Young Researcher Program, the Institute for Information & Communications Technology Planning & Evaluation (IITP), and the AI Semiconductor Graduate School Support Project.
2025.07.07 View 1276
Development of Core NPU Technology to Improve ChatGPT Inference Performance by Over 60%
Latest generative AI models such as OpenAI's ChatGPT-4 and Google's Gemini 2.5 require not only high memory bandwidth but also large memory capacity. This is why generative AI cloud operating companies like Microsoft and Google purchase hundreds of thousands of NVIDIA GPUs. As a solution to address the core challenges of building such high-performance AI infrastructure, Korean researchers have succeeded in developing an NPU (Neural Processing Unit)* core technology that improves the inference performance of generative AI models by an average of over 60% while consuming approximately 44% less power compared to the latest GPUs.
*NPU (Neural Processing Unit): An AI-specific semiconductor chip designed to rapidly process artificial neural networks.
On the 4th, Professor Jongse Park's research team from KAIST School of Computing, in collaboration with HyperAccel Inc. (a startup founded by Professor Joo-Young Kim from the School of Electrical Engineering), announced that they have developed a high-performance, low-power NPU (Neural Processing Unit) core technology specialized for generative AI clouds like ChatGPT.
The technology proposed by the research team has been accepted by the '2025 International Symposium on Computer Architecture (ISCA 2025)', a top-tier international conference in the field of computer architecture.
The key objective of this research is to improve the performance of large-scale generative AI services by lightweighting the inference process, while minimizing accuracy loss and solving memory bottleneck issues. This research is highly recognized for its integrated design of AI semiconductors and AI system software, which are key components of AI infrastructure.
While existing GPU-based AI infrastructure requires multiple GPU devices to meet high bandwidth and capacity demands, this technology enables the configuration of the same level of AI infrastructure using fewer NPU devices through KV cache quantization*. KV cache accounts for most of the memory usage, thereby its quantization significantly reduces the cost of building generative AI clouds.
*KV Cache (Key-Value Cache) Quantization: Refers to reducing the data size in a type of temporary storage space used to improve performance when operating generative AI models (e.g., converting a 16-bit number to a 4-bit number reduces data size by 1/4).
The research team designed it to be integrated with memory interfaces without changing the operational logic of existing NPU architectures. This hardware architecture not only implements the proposed quantization algorithm but also adopts page-level memory management techniques* for efficient utilization of limited memory bandwidth and capacity, and introduces new encoding technique optimized for quantized KV cache.
*Page-level memory management technique: Virtualizes memory addresses, as the CPU does, to allow consistent access within the NPU.
Furthermore, when building an NPU-based AI cloud with superior cost and power efficiency compared to the latest GPUs, the high-performance, low-power nature of NPUs is expected to significantly reduce operating costs.
Professor Jongse Park stated, "This research, through joint work with HyperAccel Inc., found a solution in generative AI inference lightweighting algorithms and succeeded in developing a core NPU technology that can solve the 'memory problem.' Through this technology, we implemented an NPU with over 60% improved performance compared to the latest GPUs by combining quantization techniques that reduce memory requirements while maintaining inference accuracy, and hardware designs optimized for this".
He further emphasized, "This technology has demonstrated the possibility of implementing high-performance, low-power infrastructure specialized for generative AI, and is expected to play a key role not only in AI cloud data centers but also in the AI transformation (AX) environment represented by dynamic, executable AI such as 'Agentic AI'."
This research was presented by Ph.D. student Minsu Kim and Dr. Seongmin Hong from HyperAccel Inc. as co-first authors at the '2025 International Symposium on Computer Architecture (ISCA)' held in Tokyo, Japan, from June 21 to June 25. ISCA, a globally renowned academic conference, received 570 paper submissions this year, with only 127 papers accepted (an acceptance rate of 22.7%).
※Paper Title: Oaken: Fast and Efficient LLM Serving with Online-Offline Hybrid KV Cache Quantization
※DOI: https://doi.org/10.1145/3695053.3731019
Meanwhile, this research was supported by the National Research Foundation of Korea's Excellent Young Researcher Program, the Institute for Information & Communications Technology Planning & Evaluation (IITP), and the AI Semiconductor Graduate School Support Project.
2025.07.07 View 1276 -
 KAIST to Develop a Korean-style ChatGPT Platform Specifically Geared Toward Medical Diagnosis and Drug Discovery
On May 23rd, KAIST (President Kwang-Hyung Lee) announced that its Digital Bio-Health AI Research Center (Director: Professor JongChul Ye of KAIST Kim Jaechul Graduate School of AI) has been selected for the Ministry of Science and ICT's 'AI Top-Tier Young Researcher Support Program (AI Star Fellowship Project).' With a total investment of ₩11.5 billion from May 2025 to December 2030, the center will embark on the full-scale development of AI technology and a platform capable of independently inferring and determining the kinds of diseases, and discovering new drugs.
< Photo. On May 20th, a kick-off meeting for the AI Star Fellowship Project was held at KAIST Kim Jaechul Graduate School of AI’s Yangjae Research Center with the KAIST research team and participating organizations of Samsung Medical Center, NAVER Cloud, and HITS. [From left to right in the front row] Professor Jaegul Joo (KAIST), Professor Yoonjae Choi (KAIST), Professor Woo Youn Kim (KAIST/HITS), Professor JongChul Ye (KAIST), Professor Sungsoo Ahn (KAIST), Dr. Haanju Yoo (NAVER Cloud), Yoonho Lee (KAIST), HyeYoon Moon (Samsung Medical Center), Dr. Su Min Kim (Samsung Medical Center) >
This project aims to foster an innovative AI research ecosystem centered on young researchers and develop an inferential AI agent that can utilize and automatically expand specialized knowledge systems in the bio and medical fields.
Professor JongChul Ye of the Kim Jaechul Graduate School of AI will serve as the lead researcher, with young researchers from KAIST including Professors Yoonjae Choi, Kimin Lee, Sungsoo Ahn, and Chanyoung Park, along with mid-career researchers like Professors Jaegul Joo and Woo Youn Kim, jointly undertaking the project. They will collaborate with various laboratories within KAIST to conduct comprehensive research covering the entire cycle from the theoretical foundations of AI inference to its practical application.
Specifically, the main goals include: - Building high-performance inference models that integrate diverse medical knowledge systems to enhance the precision and reliability of diagnosis and treatment. - Developing a convergence inference platform that efficiently combines symbol-based inference with neural network models. - Securing AI technology for new drug development and biomarker discovery based on 'cell ontology.'
Furthermore, through close collaboration with industry and medical institutions such as Samsung Medical Center, NAVER Cloud, and HITS Co., Ltd., the project aims to achieve: - Clinical diagnostic AI utilizing medical knowledge systems. - AI-based molecular target exploration for new drug development. - Commercialization of an extendible AI inference platform.
Professor JongChul Ye, Director of KAIST's Digital Bio-Health AI Research Center, stated, "At a time when competition in AI inference model development is intensifying, it is a great honor for KAIST to lead the development of AI technology specialized in the bio and medical fields with world-class young researchers." He added, "We will do our best to ensure that the participating young researchers reach a world-leading level in terms of research achievements after the completion of this seven-year project starting in 2025."
The AI Star Fellowship is a newly established program where post-doctoral researchers and faculty members within seven years of appointment participate as project leaders (PLs) to independently lead research. Multiple laboratories within a university and demand-side companies form a consortium to operate the program.
Through this initiative, KAIST plans to nurture bio-medical convergence AI talent and simultaneously promote the commercialization of core technologies in collaboration with Samsung Medical Center, NAVER Cloud, and HITS.
2025.05.26 View 5530
KAIST to Develop a Korean-style ChatGPT Platform Specifically Geared Toward Medical Diagnosis and Drug Discovery
On May 23rd, KAIST (President Kwang-Hyung Lee) announced that its Digital Bio-Health AI Research Center (Director: Professor JongChul Ye of KAIST Kim Jaechul Graduate School of AI) has been selected for the Ministry of Science and ICT's 'AI Top-Tier Young Researcher Support Program (AI Star Fellowship Project).' With a total investment of ₩11.5 billion from May 2025 to December 2030, the center will embark on the full-scale development of AI technology and a platform capable of independently inferring and determining the kinds of diseases, and discovering new drugs.
< Photo. On May 20th, a kick-off meeting for the AI Star Fellowship Project was held at KAIST Kim Jaechul Graduate School of AI’s Yangjae Research Center with the KAIST research team and participating organizations of Samsung Medical Center, NAVER Cloud, and HITS. [From left to right in the front row] Professor Jaegul Joo (KAIST), Professor Yoonjae Choi (KAIST), Professor Woo Youn Kim (KAIST/HITS), Professor JongChul Ye (KAIST), Professor Sungsoo Ahn (KAIST), Dr. Haanju Yoo (NAVER Cloud), Yoonho Lee (KAIST), HyeYoon Moon (Samsung Medical Center), Dr. Su Min Kim (Samsung Medical Center) >
This project aims to foster an innovative AI research ecosystem centered on young researchers and develop an inferential AI agent that can utilize and automatically expand specialized knowledge systems in the bio and medical fields.
Professor JongChul Ye of the Kim Jaechul Graduate School of AI will serve as the lead researcher, with young researchers from KAIST including Professors Yoonjae Choi, Kimin Lee, Sungsoo Ahn, and Chanyoung Park, along with mid-career researchers like Professors Jaegul Joo and Woo Youn Kim, jointly undertaking the project. They will collaborate with various laboratories within KAIST to conduct comprehensive research covering the entire cycle from the theoretical foundations of AI inference to its practical application.
Specifically, the main goals include: - Building high-performance inference models that integrate diverse medical knowledge systems to enhance the precision and reliability of diagnosis and treatment. - Developing a convergence inference platform that efficiently combines symbol-based inference with neural network models. - Securing AI technology for new drug development and biomarker discovery based on 'cell ontology.'
Furthermore, through close collaboration with industry and medical institutions such as Samsung Medical Center, NAVER Cloud, and HITS Co., Ltd., the project aims to achieve: - Clinical diagnostic AI utilizing medical knowledge systems. - AI-based molecular target exploration for new drug development. - Commercialization of an extendible AI inference platform.
Professor JongChul Ye, Director of KAIST's Digital Bio-Health AI Research Center, stated, "At a time when competition in AI inference model development is intensifying, it is a great honor for KAIST to lead the development of AI technology specialized in the bio and medical fields with world-class young researchers." He added, "We will do our best to ensure that the participating young researchers reach a world-leading level in terms of research achievements after the completion of this seven-year project starting in 2025."
The AI Star Fellowship is a newly established program where post-doctoral researchers and faculty members within seven years of appointment participate as project leaders (PLs) to independently lead research. Multiple laboratories within a university and demand-side companies form a consortium to operate the program.
Through this initiative, KAIST plans to nurture bio-medical convergence AI talent and simultaneously promote the commercialization of core technologies in collaboration with Samsung Medical Center, NAVER Cloud, and HITS.
2025.05.26 View 5530 -
 KAIST-KT AI & SW Research Center to Open
KAIST and KT will team up to advance AI technology by co-founding the “AI and SW Research Center.” Last month, President Kwang Hyung Lee and KT CEO Hyeon-Mo Ku signed the agreement to launch the center in Daejeon by the end of the year.
The KAIST-KT AI and SW Research Center will focus on exploring original technologies and industry AI that will incorporate KAIST’s excellent R&D capabilities and KT’s future AI-based business portfolio. The center will be located at the KT’s Research Center in Daejeon.
The two sides selected 15 futuristic projects for developing original technologies in the fields of sound, vision, health, and humanistic AI. In addition, the center plans to develop an AI model that can perceive and reply to precise and complex information-based situations through human conversation and detection, sound, images, and sensing.
To lay the groundwork for next-generation markets, the center will work on five industrial AI projects in the fields of media, bio, and health. Both KAIST and KT aim to lead digital innovation and changes in lifestyles by developing a next-generation AI model to follow GPT-3 (Generative Pre-Training 3) and strengthen the global competitiveness of AI technologies.
Furthermore, KT will provide infrastructure including space, equipment, and manpower to KAIST students hoping to form a start-up. A KT accelerator for start-up cultivation and investment will also help KAIST students via a start-up mentoring program. It will also run scholarship and internship programs for students who stand out during joint research projects.
President Lee said, “KT is an excellent AI R&D partner dealing with differentiated data from diverse sectors. Through the AI core technology lab, I look forward to seeing innovative technologies that will be meaningful not only for academia, but also for industry.”
2021.06.01 View 5373
KAIST-KT AI & SW Research Center to Open
KAIST and KT will team up to advance AI technology by co-founding the “AI and SW Research Center.” Last month, President Kwang Hyung Lee and KT CEO Hyeon-Mo Ku signed the agreement to launch the center in Daejeon by the end of the year.
The KAIST-KT AI and SW Research Center will focus on exploring original technologies and industry AI that will incorporate KAIST’s excellent R&D capabilities and KT’s future AI-based business portfolio. The center will be located at the KT’s Research Center in Daejeon.
The two sides selected 15 futuristic projects for developing original technologies in the fields of sound, vision, health, and humanistic AI. In addition, the center plans to develop an AI model that can perceive and reply to precise and complex information-based situations through human conversation and detection, sound, images, and sensing.
To lay the groundwork for next-generation markets, the center will work on five industrial AI projects in the fields of media, bio, and health. Both KAIST and KT aim to lead digital innovation and changes in lifestyles by developing a next-generation AI model to follow GPT-3 (Generative Pre-Training 3) and strengthen the global competitiveness of AI technologies.
Furthermore, KT will provide infrastructure including space, equipment, and manpower to KAIST students hoping to form a start-up. A KT accelerator for start-up cultivation and investment will also help KAIST students via a start-up mentoring program. It will also run scholarship and internship programs for students who stand out during joint research projects.
President Lee said, “KT is an excellent AI R&D partner dealing with differentiated data from diverse sectors. Through the AI core technology lab, I look forward to seeing innovative technologies that will be meaningful not only for academia, but also for industry.”
2021.06.01 View 5373